はじめに †
『翻訳Modの原理』は単純に言えば『海外言語データを日本語に置き換える』事です。
ごくまれに『日本語化パッチを入れれば全部日本語になる』と誤解する方が居ます。
大抵は『日本語化パッチに翻訳済みデータが入っている』と誤解しているのでしょうが、
『日本語化パッチ内に翻訳を行う小人さんが居て自動的に訳している』
という感じに考えている節がある人が時折現れるのはいやはやとは思わなくも無いですけど。
さて、Oblivionのゲームの仕様上で『日本語に置き換える』には幾つかの方法が有ります。
それを理解しておけば以下の流れも分かりやすくなると思うので先ず最初に解説しておきます。
基本的方法 †
公式Toolの
CSのみでも実現できる方法です。
基本的方法01 †
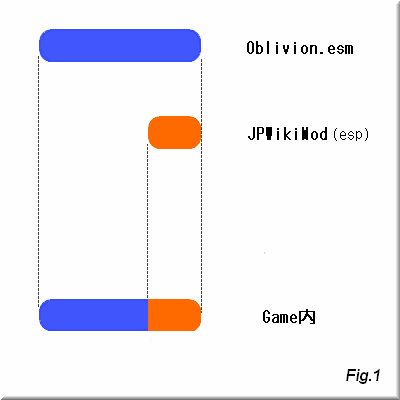
典型的な例であるJPWikiModを例に挙げます。
画像での説明で一目瞭然の様に、Oblivion.esmのデータを上書きする形になっています。
ゲーム開始時のLoadは全てのesm/espを読むと推測され、しかも日本語Modの上書き範囲は広範に渡るので、
ゲーム開始時のLoad時間はとても長くなります(試しに日本語Modを外せばすぐに分かります)。
これは
CSではesmファイルを編集できない為こうせざるを得ないのです。
基本的方法01' †
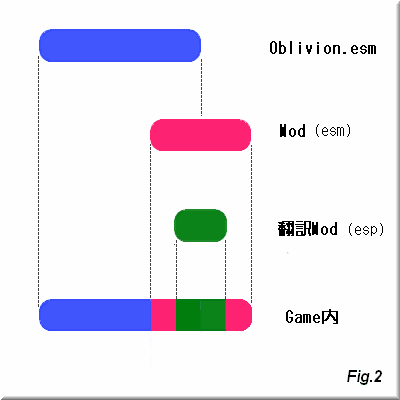
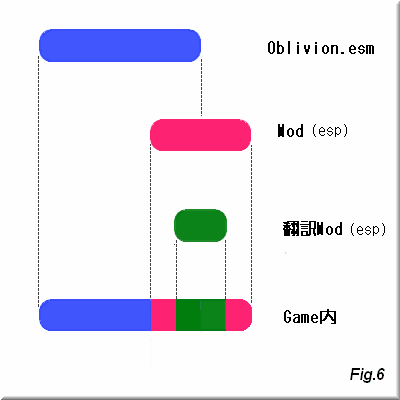
さて、次はModの例です。
Modの実装形態は2種類あります。
esmファイルによるものとespファイルによるものです。
esmファイルによるModは上述の通り、
CSでは編集ができません。
そこでJPWikiModと同じように追加でespファイルを作成する事になります。
構造がちょっと複雑になっただけで原理はJPWikiModと全く同じです。
ここで『
CSじゃesmが編集出来ないのになんでesmなModがあるの?』ということに気付いた方は鋭い。
実はesmファイルを編集/作成する方法は存在します。
ですが公式Toolである
CSだけでは不可能で有志によるToolを導入して初めて可能になるとだけここでは述べておきます。
基本的方法02 †
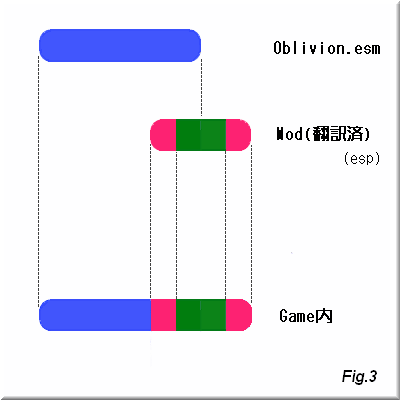
espファイルによるModは
CSでの編集が可能です。
ならばespファイル内のデータを日本語に書き換えるだけで翻訳Modができちゃいます。
この方法だと重複するデータがなくなるのでJPWikiMod(及びその派生版)で顕著に現れるようなLoad時間の増加はかなり防ぐ事ができます。
但し、オリジナルのespファイルを修正する事によるデメリットも生じます
(特に配布時に影響する。
補足:日本語化のデータの配布方法にまとめ有り)。
イレギュラーな方法 †
公式Toolの
CSだけでは実現できない方法です。
イレギュラーな方法01 †
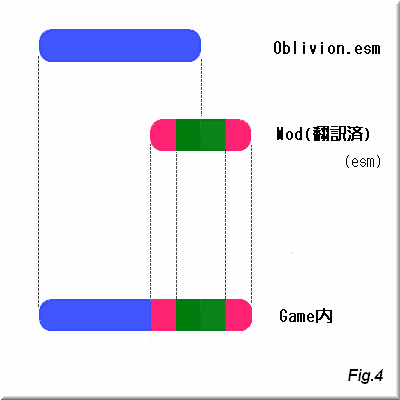
さて、以上が基本的な翻訳Modの構造になる訳ですが、その他にも方法は有ります。
先ずは『esmファイル自体を編集する』という方法です。
『
CSでは編集できない』のであれば『
CS以外で編集する』、若しくは『
CSで編集できるようにする』という方法でこれを実現できるのです。
画像が
基本的方法02のFig.3とほぼ同じですが、実際、仕組みは全く同じです。
この方法のメリットはesm/espファイルの数を節約できる事と読み込みデータ数を減らす事によるゲーム開始時のLoad時間の短縮が挙げられます。
デメリットはesmに修正を行う事になる為、翻訳Modの提供や利用時に若干不便さが発生する事です
(
補足:日本語化のデータの配布方法に或る程度まとめ有)。
この手法はこの文書では扱う内容ではないので詳しくは触れませんが幾つかの実際的方法を書いておきます。
『TES4Editで編集する』(esmファイルの編集も可能)
『Wrye BashやTES4Geckoのesm/espの変換機能を利用する』(espに変換し
CSで編集、esmに戻す)
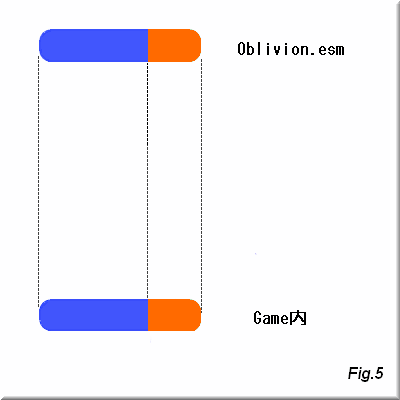
尚、この方法を行えばOblivion.esm+日本語ModのLoad時間の激増問題を理論上回避できます。
これを実験して公開されている方も居られるので2chのスレッドを探してみると良いかもしれません。
イレギュラーな方法02 †
もう一つ、
CSのみでは実現できない翻訳手法があります。
それは『espファイルをMasterにする』方法です。
CSはesmをMasterにしたespしか作成出来ないのです。
しかし有志の皆さんの開発力は偉大でして、あるespファイルに任意のespをMasterにするように変更するようなToolが幾つか開発されました。
これを利用すればespファイルで提供されるModもJPWikiModのようにespファイルを追加するだけで日本語化が出来るようになります。
画像が
基本的方法01'のFig.2とほぼ同じですが、要するに仕組みは全くそれと同じです。
この方法のメリットはespファイルを追加するだけでよいので利用者にとっては極めて楽です(但し、ロードオーダーを必ず、『Masterにしたespファイル』→『翻訳Mod』としなくてはならない)。
また、オリジナルのespには修正を加えないのも利点でしょう。
逆に、espの追加はesm/espの数の上限(約255)を圧迫するのはデメリットです。
また、ゲーム開始時のデータ読み込み量が増えるのでLoad時間が長くなると思われます
(同じく
補足:日本語化のデータの配布方法に或る程度まとめ有)。
どの方法で作成すべきか †
基本的には翻訳したいModの形態にあわせて臨機応変で選択しましょう。
また、利用者の事を考えつつも翻訳者が一番楽な形態を選択するのが良いと思います。
補足:日本語化のデータの配布方法に配布という観点からの比較まとめもあります。
但しこの文書は初心者向けという観点から、基本的手法にのみ焦点を絞りイレギュラーな方法の解説は行いません。
イレギュラーな手法を行いたいとしても、先ずは基本的な事を押えるべきですし、それを押えれば解説など無くとも
イレギュラーな手法を理解及び実行できると思うからです。
その辺を踏まえたうえでこの文書をお読み下さい。
Oblivionの翻訳を行う際の手法は色々進歩を遂げています。
この項では2011年時点での推奨方法を解説します。
尚、段階毎のナンバリングが飛び飛びだという事に気付いた方が居られるかもしれません。
これは従来の手法からやらなくて良くなったものを除外したからです(つまり、抜けている部分だけ楽になった!)。
従来の手法も資料として残してありますので比較してみると面白いかもしれません。
[B] 翻訳したいModのテキストデータを抽出 †
Mod(単体)のデータを抽出します。
手順 †
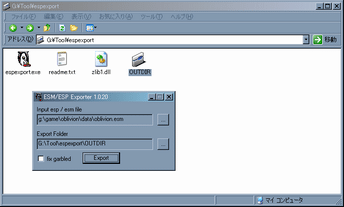
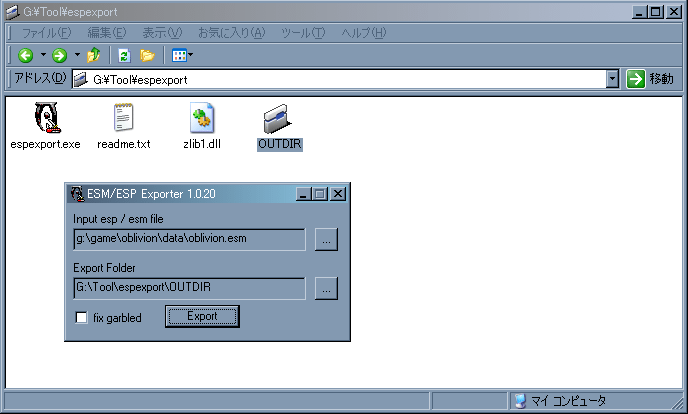
- espexportで翻訳したいModと出力ディレクトリを指定し、Export
espファイル、出力ディレクトリ共にD&Dが可能
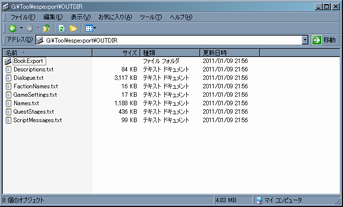
- 出力ディレクトリにExportされているか確認
開いてチェックしてみる事
補足:その他 †
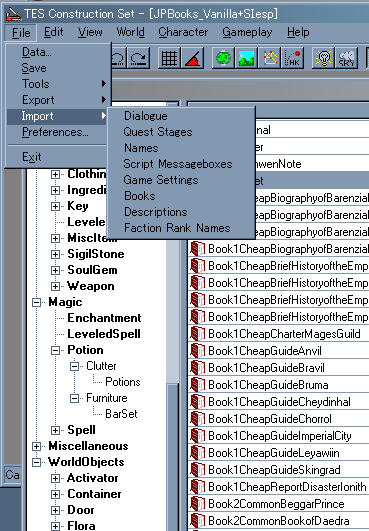
-
espexportというすばらしいToolのお陰で一発でesm/espファイル内のデータだけを取り出すことが出来るようになりました。
CSだけではそれを行うのはかなりの作業が必要だったのです(旧版参照の事)。
- ScriptのMessageBox関数の出力内容に改行が含まれていた場合、CSでは上手く出力されない問題があります。
ただこれは恐らくバグではなく仕様じゃないかと思われます(本来改行を含む出力を想定してないと思われる)。
-
Oblivion Script Extender (OBSE)には新たなOutput命令が追加されており、それらの出力データも翻訳対象となりえます。
しかし、OBSEからCSを起動したとしてもそれらの追加命令の文はexport出来ません。
それをもespexportというToolは解決してくれます。
-
一部の文字が化ける事があります。
これは英語圏で作成された文章の多くはISO-8859-1(Latin-1)、或いはWindows-1252が使用されているのですが、
これは日本語環境(Shift_JIS)では完全に表示が出来ないのです。
これはTool等の不具合ではなくやむをえないものです。対応策は補足:文字化けの項で述べます。
FormIDの頭2文字は場合によっては注目すべきです。
とりあえず、説明する前に例を見てみましょう。
例えば、Oblivion.esm内に存在するGoblinのFormIDはこうなります(Namesカテゴリより)。
00 Oblivion.esm
------------------------------------------------------------
FormID: 000C9FFC CGGoblinLogRunner02 CREA Goblin
次に、Oblivion.esmをMasterとするFrancesco's Leveled Creatures-Items Mod.esm内によって追加されるGoblinは次のものが居ます。
00 Oblivion.esm
01 └ Francesco's Leveled Creatures-Items Mod.esm
------------------------------------------------------------
FormID: 0101E65A FranCreaGoblin1NoBehav CREA Goblin
更に、Oblivion.esmとFrancesco's Leveled Creatures-Items Mod.esmの両者をMasterとするFrancesco's Optional New Creatures Add-On.esmで追加されるGoblinには次のものが居ます。
00 Oblivion.esm
01 └ Francesco's Leveled Creatures-Items Mod.esm
02 └ Francesco's Optional New Creatures Add-On.esm
------------------------------------------------------------
FormID: 020182D9 FranCreaNewGoblin01a CREA Goblin
お気づきでしょうか?
FormIDの頭がカウントアップされている事に。
つまり、FormIDの頭2文字をチェックすることでそのデータ行がどのesm/esp由来か特定する事ができる様になります。
但し、これは『追加』データに関してのみ言える事で、『変更』データ部分
(esm/espがOblivion.esmのデータを上書きする場合)はFormIDが変更されないので両者のデータを比較する事でしかチェックできません。
これはespexportを使用して翻訳する範囲では気にする必要はありませんが押えておくと役に立つ事があるかもしれません。
余談ですが、コンソールからAdditemする場合にID頭2文字をModのロード順から来るIDに置き換える事(これから察するに一つのesp/esm内に格納できるデータは0xFFFFFF個、即ち16,777,215までと推測される)や導入できるesp/esmの上限が約255(00〜FE)である(FFはシステム予約)なのもこれと根源は同じでしょう。
[D] テキストデータ翻訳 †
翻訳は基本的に英文の部分を日本文に置き換えるだけですが幾つか知っておくべき点が有ります。
共通事項として、翻訳作業はShift_JISで行う必要がある事を記憶して置いてください。
尚、表示例では半角スペースをアンダースコア"_"に置換していますが、
現行の日本語化パッチでは不要な処理である事をここに触れておきます(半角スペースをアンダースコアにするとテキスト処理等で幾らか不便になる)。
手順 †
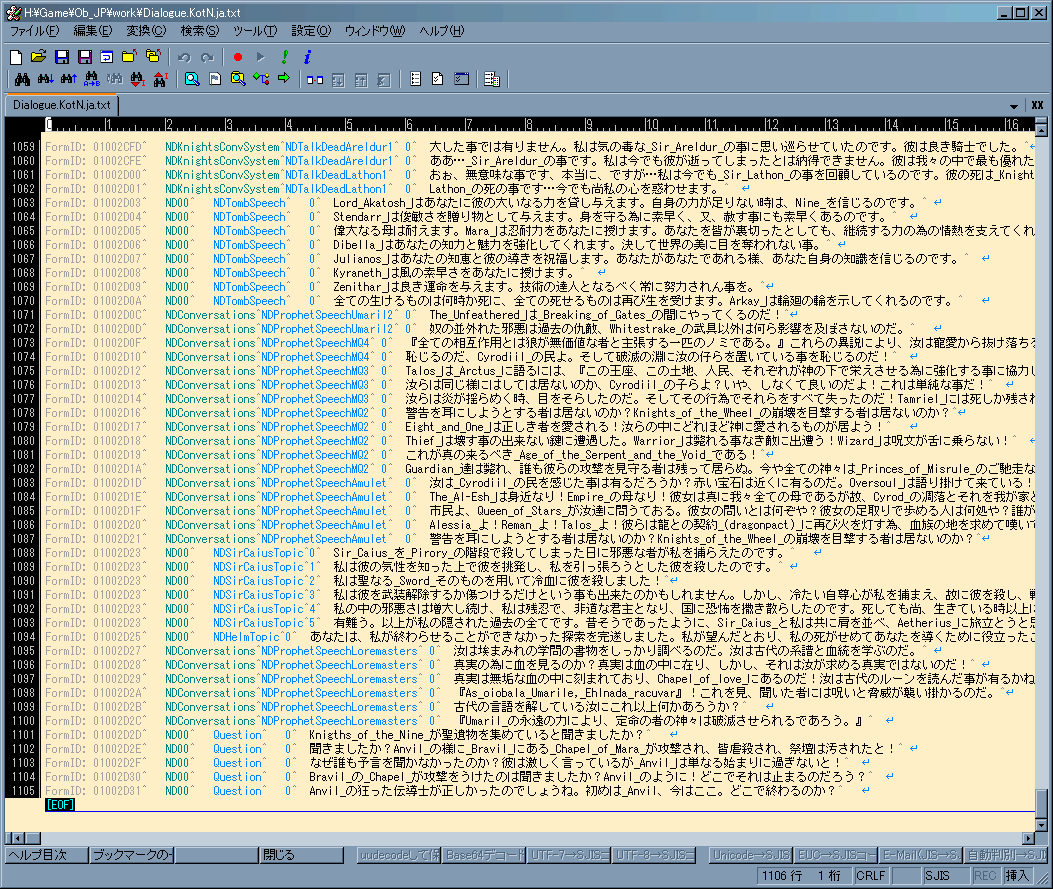
Dialogue †
- 会話の字幕部分
- 英文の後にタブを挟んで又色々文が有る事があるが、これは台詞を喋るときの指示や注釈
(CS
1.2では出力されない)。
故に、英文の後にタブがある場合は、それ以降は訳さなくてよい。
逆に言うと、タブを挟むとそれ以降はゲーム内に反映されないので注意が必要
(訳文部分にタブを混入させてはいけない)
- CS
上では1データあたりに入力できる文字列長には制限が有る
(150文字。『バイト』で無いのに注意。マルチバイト文字は1文字と判定される模様)。
外部からのimportでその制限を回避できるかは未検証だが、長過ぎるとゲーム内で表示できない事に繋がるので意識する方が良いと思われる
(制限を緩くするだけならConstructionSetあれこれ)。
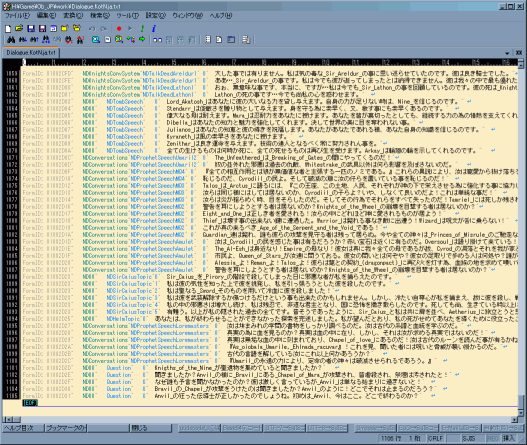
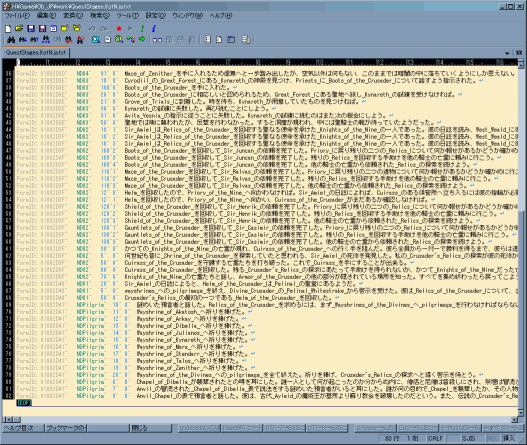
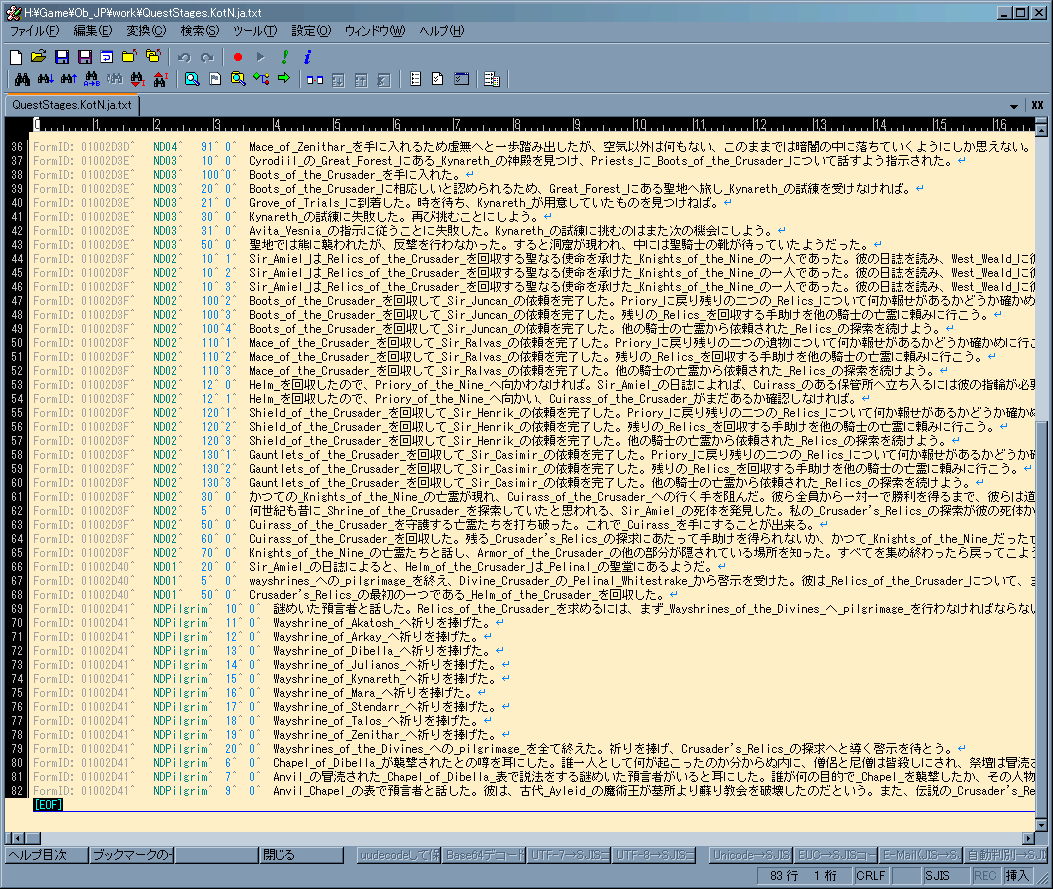
Quest Stages †
- ジャーナルのクエスト関連の文
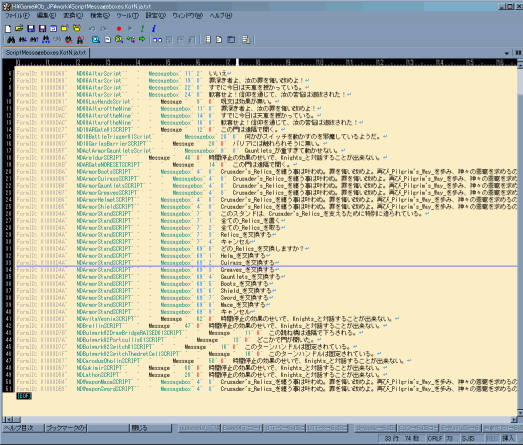
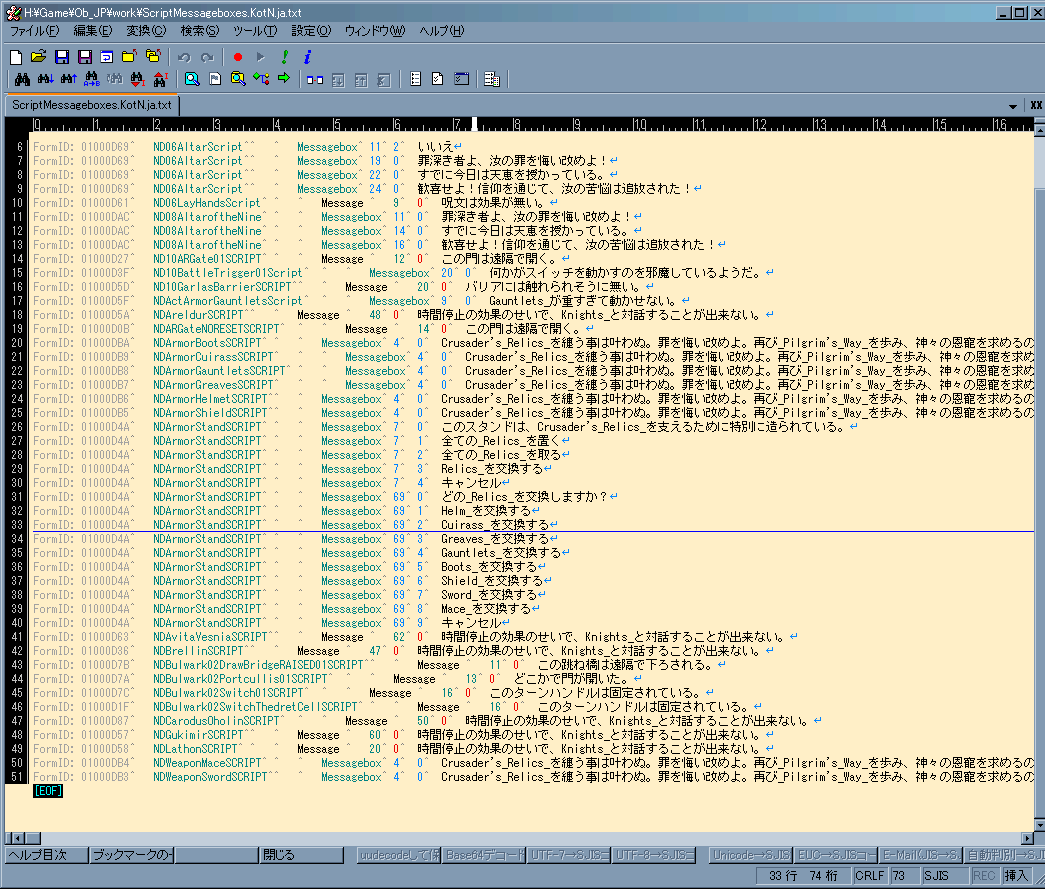
Script Messageboxes †
- Scriptが出すメッセージ
- ノーマルなOblivionでは Message と MessageBox 関数が殆どである
(VanillaではそのほかにもSetCellFullNameやSetActorFullName、EssentialDeathReloadもごく少ないがexport対象になる)
- Oblivion Script Extender使用のModの場合はそれ以外もありうる(MessageBoxEX等。但しこの関数は非推奨になっている)
- メッセージ内にダブルクォートが使用できないのは当然として、加えて半角セミコロン(;)も使えない模様。
恐らくそれ以降がコメントとして解釈されてしまうせいと思われる。
-
行番号はScriptの開始行を0とし、空行を無視した場合の物。
オプション番号は最初のオプション位置を0としてカウントアップ
EditorIDはNamed Scriptの場合はScript Editorで確認できるScript名なので分かりやすい。
しかし、Result Scriptの場合はそれが貼り付けられているデータ(台詞等)のIDなので探しにくい。
検索(MenuBar → Edit → Find Text)を駆使して探すのが一番手っ取り早いと思う。
■ 文法
[FormID] [EditorID] [関数名] [行番号] [関数の幾つ目のオプションか] [出力文字列]
■ 例 #1
[実際のコード] HogeScriptというScript
Message "変数の値(変数1:%.0f, 変数2:%+-5.0f)", Var01, Var02
[exportデータ]
FormID: 01234567 HogeScript Message 5 0 変数の値(変数1:%.0f, 変数2:%+-5.0f)
■ 例 #2
[実際のコード] HogeScriptというScript
MessageBox "メッセージボックスタイトル (%.0f, % 5.2f, % .3e, %g)", Var01, Var02, Var03, Var04, "ボタンA", "ボタンB", "ボタンC"
[exportデータ]
FormID: 01234567 HogeScript MessageBox 10 0 メッセージボックスタイトル (%.0f, % 5.2f, % .3e, %g)
FormID: 01234567 HogeScript MessageBox 10 1 ボタンA
FormID: 01234567 HogeScript MessageBox 10 2 ボタンB
FormID: 01234567 HogeScript MessageBox 10 3 ボタンC
- 翻訳対象文字列内の"%.0f"や"% 5.2f"のような"%"で
始まるものはScript内の変数に置換される部分。
何に置換されるかは英文から推測は出来るがきちんと確認したい場合は
CSで当該のScriptを見るのがベスト。ある程度のScriptへの理解は必要だと思う
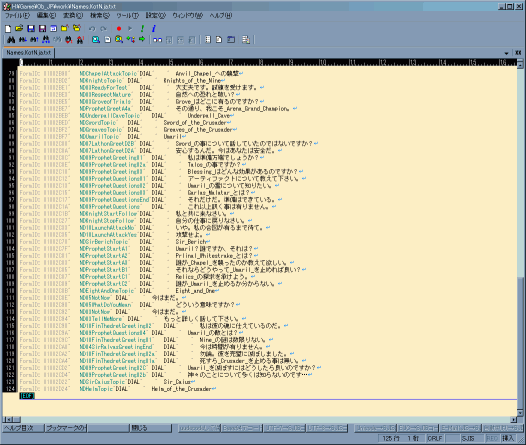
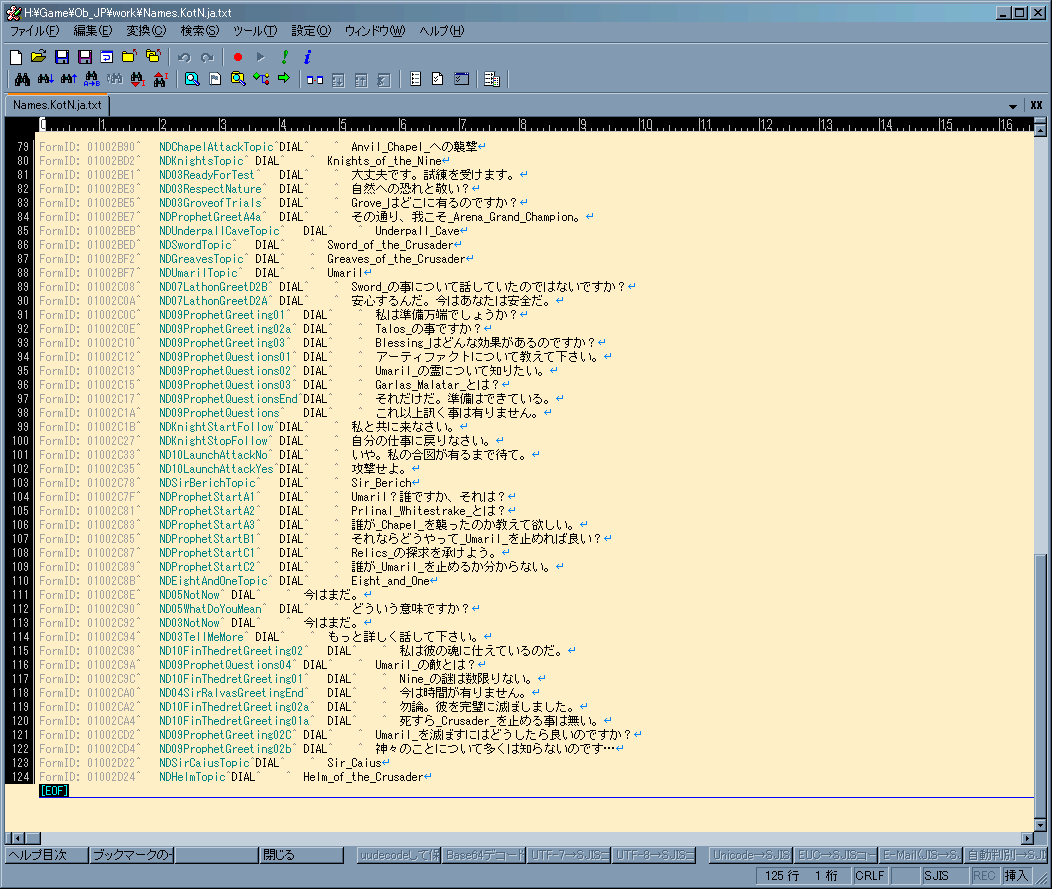
Names †
- 各種オブジェクト、MOB/NPCの名前や会話での選択
- 全て訳せるなら良いが、面倒ならばサブカテゴリ、DIALの部分だけでよい
(DIALは会話時の選択肢になる)。
- CS
上ではDIAL部分に入力できる文字列長に制限が有る
(38bytes。Dialogueと異なり、文字数ではなくbyte単位)。
外部からのimportでその制限を回避できるかは未検証だが、長過ぎるとゲーム内で表示できない事に繋がるので意識する方が良いと思われる
- サブカテゴリ、RACEは翻訳してはいけない。
これを翻訳するとゲーム内でキャラの喋る音声が出なくなってしまう
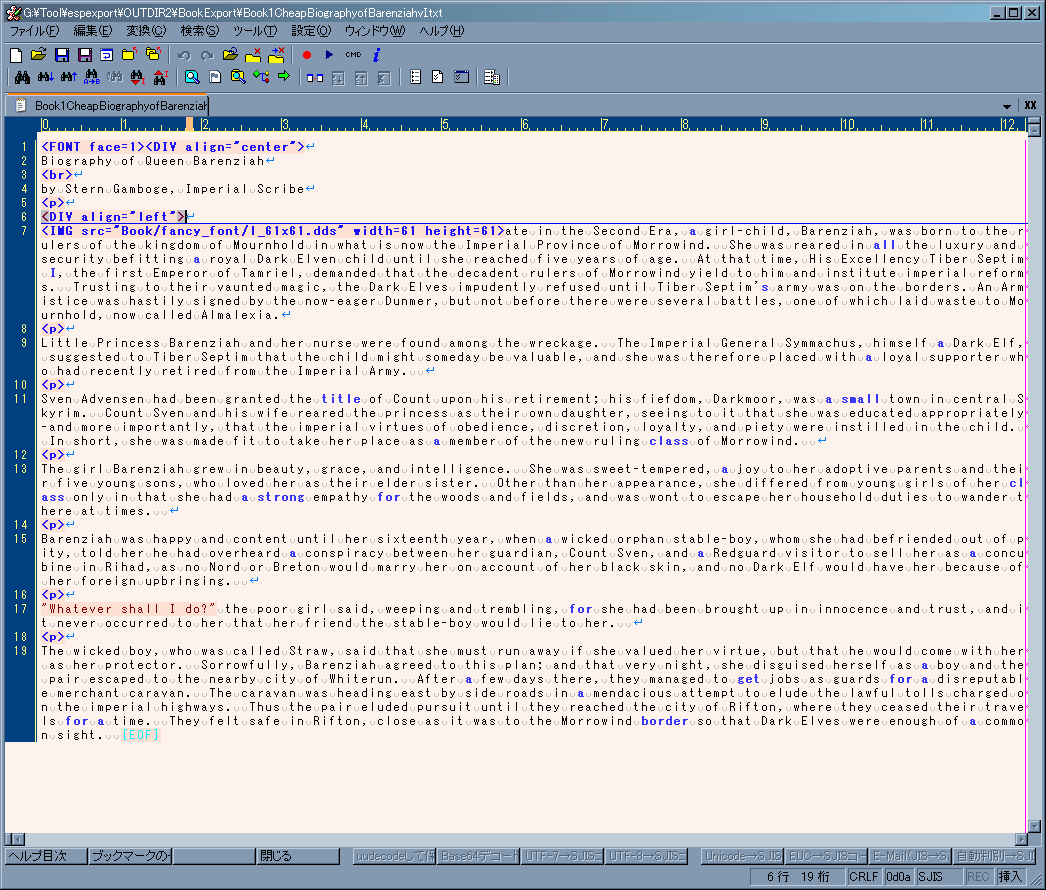
Books †
-
書籍ではHTMLに似た簡易HTMLが使用できる。
本文がタグで始まる場合は簡易HTMLモード、そうでない場合はテキストモードで表示される。
但し、タグの前に空白文字(スペース、改行、タブ)が有った場合は判定に於いて無視される
また、日本語の文字もこの判定では空白文字扱いである(実害は無いが気をつけるべき仕様)。
- Dialogue等と異なり、本文にダブルクォートが使用できる
-
簡易HTMLではFontを弄る事が出来るが、Daedric Fontが割り当てられている部分には注意する事
(font face=4)。
Daedric Fontには半角英数しか含まれていない。よって半角英数以外の文字をDaedric Fontで表示することは恐らく想定されていない。
日本語の文字にDaedric Fontを当てた場合、GameがCTDを起こす事が有る。
Daedric Fontで記された部分は大抵魔術的なフレーバーの為の部分であり、翻訳する必要はない。
- 簡易タグはCSWikiを参照の事。
一応補足:書物の簡易HTMLにも抜粋有。
GameSettings †
- 基本的にModでは殆ど利用されてないので翻訳対象になる事は稀
- Modには直接関係無いが、Vanillaでは例えば
sDeviceJoystick Joystick
のような翻訳してはいけない行もある(Joystick設定に不具合が発生するらしい)。
Descriptions †
- Loading時に流れるTipsが主
- 基本的にModではあまり利用されない。
公式ModですらDLC9でしか使われてない(KotNでも使われてない。
SIでは幾つか使用されている)
FactionNames †
- ゲーム内のFaction(組織)のRankの名前。ゲーム内には余り出てこないので気にされないことが多い
- DialogueやQuestStageにRank名が出てくるような場合は気をつけなくてはならないだろう
- Quest等でFaction内のRankの高さを判定するようなものは有るが、
用意されている関数はRank名自体ではなくRankに割り当てられているIndex番号で判定する(GetFactionRank)。
よってRank名の翻訳は特に問題は無い
補足:文字化け †
解読 †
解読するだけなら文字コードを指定して開く事の出来るアプリを利用すれば大体いけます。
文字コードを何に設定するかを試行錯誤する必要がありますが、ISO-8859-1(Latin-1)かWindows-1252にすれば大抵は成功します。
Windows-1252はISO-8859-1のMS的拡張なのでWindows-1252の方の可能性が高いでしょう(大抵はWindowsで開発されているので)。
英語と独語はISO-8859-1(かWindows-1252)でほぼいけます。
仏語、露語等はISO-8859-1(やWindows-1252)では表示しきれない事が有りますがそれでも適切に文字コードを設定すれば文字化けは解消されます(その言語が読めるかはあなた次第)。
文字コードを指定して開く事の出来るアプリには、MS Office、OpenOffice.org及び大抵のWebブラウザが挙げられます。
特にWebブラウザは大抵の環境で導入されている上にかなり広範な文字コードに対応しているので一番手軽かと思います
(当該のファイルをWebブラウザにD&Dしてブラウザの読み込み文字コードを弄れば良い)
厳密な解読 †
厳密に解読したい場合は文字化けしているファイルをバイナリエディタで開き、文字化け部分の値を調べます。
その後、ありえそうな文字コードで当該の値を検索するのがセオリーです
(というか、虱潰しでチェックするという方が正確か)。
バイナリの値で言えば0x80-0xFF辺りに着目すれば良いです。
Windows-1252とISO-8859-1を区別したい場合は0x80-0x9F付近に着目です。
解読したらどうする? †
基本的に文字化けするものはASCIIの範囲の文字で代用が出来ますのでその様にするのが適当でしょう。
大した量も無いでしょうし手作業で置換して大丈夫でしょう。
やってはいけない事 †
文字化けしているファイルを文字化け文字を解読前に編集して保存してはいけません。
必ず文字化け解読後に編集すべきです。
何故かと言うと、文字化けとはエディタ(等のアプリ)が文字コードの判別に失敗している状態であり、
不正確な判定を元に処理する事はオリジナルのデータの変更(バイナリデータの変化)を伴う可能性が高いからです
(例えば『あ』という文字であっても、そのバイナリはShift_JISは0x82 0xA0、EUC-JPは0xA4 0xA2、UTF-8は0xE3 0x81 0x82である)。
エディタにも内部処理コードがShift_JISのものとUnicodeの物がありますが、この問題に関してはどちらも大差がありません
(内部コードShift_JISの方が可能性として化け易くはなるが)。
文字化けの捜索 †
先ず最初に文字化けを発見する事が大事であるのは分かりました。
しかし、その対象データが多い場合は目視での捜索は大変です。
データを翻訳しながら文字化けっぽい部分があったらオリジナルデータを参照するというのはそう悪い戦略ではありません。
ですが、エディタ等によっては文字化けが分かりにくいものも有ります(表示出来る文字が無い時は見掛けをスペースにしてしまう物とか)。
よって厳密を期したいならば他の手をとるべきでしょう。
ではどうすれば良いのかと言うと、正規表現で検索(若しくはGrep)できるエディタを使います。
ASCIIの範囲の文字ならば日本語環境でも化けない事を利用し、それ以外の文字が存在しないか検索するのです。
ASCIIの範囲の文字を正規表現で表記すると、 [\x00-\x7F] となります。
それ以外の文字を見つけたいので、その否定表現の [^\x00-\x7F] を使って検索すれば良い筈です。
上手く行かない場合は [^\x{01}-\x{7F}] で試してみてください。
何故文字化けするのか †
『英語圏ではASCIIで表現できるんだから文字化けするはず無いじゃん』とお考えの方。
それは間違っていません。
ただし、『ASCIIの範囲の文字を使用しているならば』という条件が付きます。
英語圏ではISO-8859-1(Latin-1)かWindows-1252という文字コードが良く使用されますが、これらには
日本語環境で多用されるShift_JISとは異なる文字が割り当てられているエリアがあります
これらの文字が使用されるとShift_JISで表示できず、文字化けるのです。
また、日本語環境では文字コード判定の優先度がShift_JISの方が高いのもあるかと思います。
以下に文字化けの例を挙げます。
例ではHTML上の工夫(文字参照)をしてWindows-1252で使用される文字を表示しています。
一応表示は出来ていますが、本来はシングルバイト文字なのにマルチバイト文字になっています。
これにより文字コードというものが一筋縄では行かないものである事がお分かりになると思います。
また、その表示できない文字と次の文字が組み合わさって偶然Shift_JISの文字になる事があります。
英文中にいきなり漢字の文字化けが出るのは大抵これです。
しかし、必ず漢字になる訳ではなく、Shift_JISに該当する文字が存在しない組み合わせになる事があり
これはその組み合わせやエディタやその設定によって表示が異なります(何も表示されなかったり中黒になったり等)。
寧ろそちらの方が多いかもしれませし、表示されないと言う事は見つけにくい、或いは
字面から判断しにくいという事も覚えておくと良いかもしれません。
その場合は文字コード指定で読み込めるアプリを使うしかありません。
余談ですが、以下の組み合わせ例で漢字が全て "chi"なのはなかなか興味深いことです
(Shift_JIS設計時にそうしたのでしょう)。
Windows-1252とShift_JISでの文字化けの例
Windows-1252の例は日本語環境で正確に表現できないので文字コード上で同等とされる文字で表現。
Shift_JIS (CP932) Windows-1252 (CP1252)
======================================================================
0x82 該当文字なし ‚
0x85 該当文字なし … (正しくは一文字で ... をあらわした物)
0x91 該当文字なし ‘
0x92 該当文字なし ’
0x93 該当文字なし “
0x94 該当文字なし ”
----------------------------------------------------------------------
0x82 0x50 1 ‚P
0x82 0x51 2 ‚Q
0x92 0x6D 知 ’m
0x92 0x6E 地 ’n
0x92 0x6F 弛 ’o
0x92 0x70 恥 ’p
0x92 0x71 智 ’q
0x92 0x72 池 ’r
0x92 0x73 痴 ’s
0x92 0x74 稚 ’t
0x92 0x75 置 ’u
0x92 0x76 致 ’v
----------------------------------------------------------------------
0x82 0x20 該当文字なし ‚ (二つ目の文字は半角スペース)
0x85 0x20 該当文字なし … (二つ目の文字は半角スペース)
0x85 0x21 該当文字なし …!
0x85 0x22 該当文字なし …"
0x85 0x27 該当文字なし …'
0x85 0x29 該当文字なし …)
0x85 0x3F 該当文字なし …?
----------------------------------------------------------------------
夫々の文字コードの構成の概要は次の通りです。ISO-8859-1の0x80-0x9Fの部分の
制御文字は文章を書くという点ではほぼ無関係と言えます。
よってその領域を記号に割り当てているWindows-1252は実用上、ISO-8859-1の上位互換に
相当します。
ISO-8859-1&Windows-1252&Shift_JIS
| ISO-8859-1 | Windows-1252 | Shift_JIS
======================================================================
0x00-0x7F | ASCII領域(共通)
----------------------------------------------------------------------
0x80-0x9F | 制御文字 | 図形文字 | 漢字/記号の1バイト目含む
----------------------------------------------------------------------
0xA0-0xFF | 記号及び特殊アルファベット類 | 半角かな含む
----------------------------------------------------------------------
元の文字コードが分かれば文字コード変換Toolでの変換も可能です。
但し、日本で公開されているToolの多くは海外の文字コードに対応して無いものが多いです。
コマンドラインツールになりますが、
iconv(Unixの分野で利用されている。WindowsではCygwinやGnuWin32等を導入すると利用できる)
が対応文字コードの点では便利でしょう。
但し、iconvはnkfと異なり、文字コード自動判定機能はありません。
以下は全て同じ意味です。
> iconv --from-code=WINDOWS-1252 --to-code=SJIS INPUT.txt > OUTPUT.txt
> iconv -f WINDOWS-1252 -t SJIS INPUT.txt > OUTPUT.txt
> iconv -f CP1252 -t MS_KANJI INPUT.txt > OUTPUT.txt
Toolでの一括変換は予期せぬ結果になる事が有るので必ず事後にDiffを取って変換結果を確かめるべきです。
例えば0x85はWindows-1252では ... を1文字で表したものになりますが、これをShift_JISに変換すると
…(三点リーダ)に変換されます。
文字コードの変換的には正しいのですが、シングルバイトの半角英数にマルチバイトの
記号が入るのは(少なくとも当方の感覚では)美しくありません。
この場合は素直にドット3つ "..." で置換するのがベストな解決法でしょう。
実際、同じような文でその様な記号が必要な時はドット3つで大抵は記述されています。
つまり、その部分の文を書いた人の(語弊はあるが)ミスであると推測されます。
ここで一つ注意してください。それは使用するFontにより表示される文字が異なる事があると言う事です。
以下の例をご覧下さい。
■ 三点リーダ
MSゴシック:…
Verdana :…
Gulim :…
■ 円記号
MSゴシック:\
Verdana :\
Gulim :\
■ チルダ
MSゴシック:~
Verdana :~
Gulim :~
■ 波ダッシュ
MSゴシック:〜
Verdana :〜
Gulim :〜
HTMLソースを見て貰えばお分かりの通り、Font指定が異なるだけで夫々は同じ文字です。
余り大きな問題ではありませんが、一応念頭においておくべきかと思います。
文字化け等の問題は文字集合(文字コード)だけではなくFont(PC設定やFont Link等)やお国柄事情等いろんな要素が絡んできてかなり複雑なのです
(Unicodeにおける波ダッシュとその対策等はその良い例)。
話を本題に戻しまして、実際のOblivionのデータ内でどれだけASCII以外の文字が
使われているのかと言うと、かなり少ないです。
Vanillaなデータではあの膨大なデータ量にも拘らずASCII範囲外の文字が使われた例は数えるほどしかありません(しかし、Fallout 3ではかなり増化していた)。
SIの領域もそんなに目に付きませんでした。
ところが、(品質管理の徹底度がVanillaより低いと思われる)DLCでは
そんなにデータが無いにも拘らず文字化け箇所は沢山有ります。
使用文字チェックは適当なScriptでも簡単に出来るような事
([^\x00-\x7F]でgrepするだけで良い)なのですが
それでもそこまで多いのは気をつけないとどうしても混入してしまうと
いうことなのかもしれません。
日本語環境であっても場所と場合によって使えない文字記号があります。
それを一応なりとも把握している人は多くない事(半角カタカナ、
丸囲み文字が駄目と言われてもどうして駄目なのか、何処で駄目なのか、
何処なら使っていいのか説明できる人は多くないでしょう)
から類推するとどうしようもない事なのでしょう。
尚、文字化けした英文をそのままにして日本語化パッチを導入した
Oblivionで表示すると多分文字化けそのまま出力されるんじゃないかと思います。
日本語化パッチ無しなら多分文字化けしない気がします。
補足:書物の簡易HTML †
CSWiki等を見れば詳しく載っていますが一応抜粋しておきます。
一つだけ覚えて置いて欲しいのは、この簡易HTMLは実際のHTMLの感覚で使うとはまります。
実際のHTMLとは似て非なるものであり、凝った使い方をしようと考えない方が良いと思います。
まあ、HTMLレンダリングエンジンは案外高度な物なので独自実装と思われるこの簡易HTMLが
色々怪しいのもやむをえないとは思います。
<font> †
- 文字の使用フォントと色を指定できる
- 終了タグは</font>。省略してもエラーにはならない
- 終了タグが有るのでネスト(入れ子構造)を作成できるが、効果は無い(実際のHTMLとの相違)。実際のHTMLのpタグの様に前のタグを終了させてしまう。
- 色の指定はRBG値。但し実際のHTMLと異なり、#は不要
- 現行の日本語化パッチではPCのTrueTypeFontを使用するようになっているのでFont指定はプレイヤー環境に依存
- 例
<font face='Kingthings_Regular'>Kingthings_Regular.fnt
<font face='Kingthings_Shadowed'>Kingthings_Shadowed.fnt
<font face='Tahoma_Bold_Small'>Tahoma_Bold_Small.fnt
<font face='Daedric_Font'>Daedric_Font.fnt
<font face='Handwritten'>Handwritten.fnt
<font face='1'>Kingthings_Regular.fnt
<font face='2'>Kingthings_Shadowed.fnt
<font face='3'>Tahoma_Bold_Small.fnt
<font face='4'>Daedric_Font.fnt
<font face='5'>Handwritten.fnt
<font color='ff0000'>赤い文字
黒<font color='ff0000'>赤<font color='0000ff'>青</font>黒</font>黒
上のFontタグの例を実際のHTMLで記述すると次のように表示される。4文字目に注目。違いを確認されたし。
黒<font color='#ff0000'>赤<font color='#0000ff'>青</font>黒</font>黒
黒赤青黒黒
<div> †
<img> †
<br> †
- 強制改行。
- 属性なし。終了タグなし。
- 書籍データの一番最初に記述された場合は例外的に改行が行われない
<p> †
- 強制改行。
- 属性なし。終了タグなし。
- <br>と同じだが、改行の幅は2行
- 本来のHTMLを知っている人にとっては最も違和感があるタグかもしれない
<hr> †
- 書物で改ページを行う。巻物では無効
- 属性なし。終了タグなし。
簡易HTMLモードとプレーンテキストモード †
書籍データは2種類の表示モード(簡易HTMLモードとプレーンテキストモード(共に仮称))があります
- 簡易HTMLモード
- 書籍データの始まりがタグの場合にこのモードになります。
但し、必ずしもタグで始めなくても簡易HTMLモードになる事が有ります
(半角スペースや改行が開始行のタグの前に有る場合。
実は全角文字が開始行のタグの前にあっても簡易HTMLモードになるが恐らくこれは想定外の事例)。
- このモードでは上のタグが解釈されます。
また、<と>で囲まれた部分は基本的に表示されなくなります。
これは簡易HTMLで使用されないタグを記述しても無視されて表示され無い事を意味します。
但し、タグ内に改行を含めた場合、その挙動はおかしくなります
- タグのアルファベットは大文字小文字を区別しません
- 属性の値を囲む記号はダブルクォートでもシングルクォートでも良いようです。属性の値が数値ならばそれらのクォート文字も省略できるようです。
- 通常のHTMLでは改行は無視されますが、簡易HTMLでもそれは同様です。改行するときはタグを使用しましょう
- 通常のHTMLでは連続した半角スペースは1つ分のスペースに表示されますが、簡易HTMLではそのまま表示されます。
つまり通常HTMLと異なり、半角スペースをレイアウト調整に使用できるということになります。
- プレーンテキストモード
- 上記簡易HTMLモードの条件に合致しない場合はこちらになります
- <や>はそのまま表示されます。改行や半角スペースも同様です
その他 †
- 日本語化パッチ環境下でのみ、アンダースコア(_)は半角スペースとして置換されて表示される(過去のバージョンの仕様を互換性の為に残してあるもの)。レイアウト調整に使えるが半角スペースでも可能であるので敢えて使う必然性は高くない
実際の表示例 #1 †
番号指定の場合は日本語化パッチの物が適用される(表示例はIPA P明朝)
Font名の直指定は無視され、番号指定の1のFontが使用される
よって、日本語化パッチを入れている環境でFontを変えたい場合は
Font名ではなく番号で指定しなくてはならない
fontタグはネストしない
<font face='Kingthings_Regular'>Kingthings_Regular.fnt</font><br>
<font face='Kingthings_Shadowed'>Kingthings_Shadowed.fnt</font><br>
<font face='Tahoma_Bold_Small'>Tahoma_Bold_Small.fnt</font><br>
<font face='Daedric_Font'>Daedric_Font.fnt</font><br>
<font face='Handwritten'>Handwritten.fnt</font><br>
<br>
<font face='1'>Kingthings_Regular.fnt</font><br>
<font face='2'>Kingthings_Shadowed.fnt</font><br>
<font face='3'>Tahoma_Bold_Small.fnt</font><br>
<font face='4'>Daedric_Font.fnt</font><br>
<font face='5'>Handwritten.fnt</font><br>
<br>
■
<font color='ff0000'>■
<font color='0000ff'>■</font>
■</font>
■<br>
1<br>
2<p>
3<br>
<br>
<hr>
<div align='right'>右寄せ
<div align='left'>左寄せ
<div align='center'>真ん中

実際の表示例 #2 †
imgタグ+brタグだけの行は表示されない
divには終了タグが無い (念の為の検証)。よってネストが無い
fontタグでdivタグの効果がリセットされる
<IMG src="Book/fancy_font/a_70x61.dds" width=70 height=61><br>
<IMG src="Book/fancy_font/e_78x61.dds" width=78 height=61> <br>
<IMG src="Book/fancy_font/f_59x61.dds" width=59 height=61>F<br>
<div align='right'>右寄せ
<div align='center'>真ん中
<IMG src="Book/fancy_font/a_70x61.dds" width=70 height=61>A<br>
</div>
<IMG src="Book/fancy_font/e_78x61.dds" width=78 height=61>E<br>
</div>
<hr>
<div align='right'>右寄せ
<div align='center'>真ん中
<IMG src="Book/fancy_font/a_70x61.dds" width=70 height=61><font color='0000ff'>a</font><br>
<IMG src="Book/fancy_font/e_78x61.dds" width=78 height=61><font color='0000ff'>e</font><br>
<div align='right'>
<IMG src="Book/fancy_font/v_63x62.dds" width=63 height=62>V<br>

実際の表示例 #3 †
fontタグでdivタグの効果がリセットされるが、正確に言えば終了タグでリセットされるっぽい
<div align='center'><font color='0000ff'>A</font><br><font color='0000ff'>B</font>C<br>
<div align='center'><font color='0000ff'>A<br><font color='0000ff'>B</font>C<br>
<div align='center'><font color='0000ff'>A<br><font color='0000ff'>BC<br>
<div align='center'><font color='0000ff'>A</font><br>
<font color='0000ff'>B</font>C<br>
<div align='center'>
<font color='0000ff'>A</font><br>
<font color='0000ff'>B</font>
C<br>

実際の表示例 #4 †
書籍データ開始部がタグで始まるならば簡易HTMLモードになるが、タグの前に半角スペースや改行があってもこの判定には影響しない。
但し、開始行のタグの前の半角スペースは表示の上では無視されない。
モード判定のタグは何でも良い。それが簡易HTMLに無いものであっても良い。
連続半角スペースであってもそのまま表示される。 -- (01)
実体参照は利用できない。よって半角の<と>を使用したい場合、簡易HTMLモードは利用できない -- (02)
通常HTMLでのコメント記法が利用できる(但し<と>に挟まれる物は表示しないというルールが適用されている可能性大) -- (03)
通常HTMLでは許される、コメント内のタグ記述は不可能 -- (03b)
通常HTMLでは文法違反な記述もコメント(若しくはタグ)と解釈される -- (03c-03g)
存在しないタグは表示されないが、改行を含めても大丈夫。
但し、>の前には必ず改行以外の何らかの文字が要るっぽい -- (04)
タグの中身が日本語の場合は上記の法則から逸脱する。
文字によっては上手く解釈されない場合がある。
日本語化パッチとの兼ね合いもあるような気もするが法則がいまいちつかめず不明。
コメント記法を含め、日本語をタグ内に記述しない方が安全 -- (05)
タグには>は本質的に不要な気配がある。
即ち<が全てのマークアップを御破算にし1からマークアップを開始するように見える。 -- (07)
<AdoringFan>
あいうえお
<br>
かきくけこ
<br>
さしすせそ
<p>
たちつてと
なにのねぬ<br>
---------- 01<br>
半角スペース*1<br>
半角スペース*2<br>
半角スペース*4<br>
半角スペース*8<br>
---------- 02<br>
"&<>
"&<>
<hr>
---------- 03a<br>
<!-- HTMLコメント(正しい記法) -->
---------- 03b<br>
<!-- <font>HTMLコメント(正しい記法)</font> --><br>
---------- 03c<br>
<!--
HTMLコメント(正しい記法)
-->
---------- 03d<br>
<!--HTMLコメント(間違った記法)>
---------- 03e<br>
<! --HTMLコメント(間違った記法)-->
---------- 03f<br>
<! --HTMLコメント--(間違った記法)-->
---------- 03g<br>
<!HTMLコメント(間違った記法)>
---------- 04a<br>
<AdoringFan>
---------- 04b<br>
<Adoring
Fan>
---------- 04c<br>
<By
Azura,
by
Azura,
by
Azura!>
---------- 04d<br>
<
By
Azura,
by
Azura,
by
Azura!
>
<br>
==========<br>
<hr>
---------- 05a<br>
<たまねぎ><br>
<あどりんぐふぁん><br>
<タマネギ><br>
---------- 05b<br>
< たまねぎ ><br>
< あどりんぐふぁん ><br>
< タマネギ ><br>
---------- 05c<br>
<!--たまねぎ--><br>
<!--あどりんぐふぁん--><br>
<!--タマネギ--><br>
---------- 05d<br>
<onたまねぎion><br>
<onあどりんぐふぁんion><br>
<onタマネギion><br>
---------- 05e<br>
<た
まね
ぎ><br>
---------- 05f<br>
<
た
ま
ね
ぎ
><br>
---------- 06<br>
<Adoring Fan>TAMANEGI</Adoring Fan><br>
---------- 07<br>
>
>
>
>
>
<
<
<
<
<
>
<br>
---------- 08<br>
<Adoring
閉じ忘れ
たまねぎ
<AdringFan>
おにゃぉーん
<br>
---------- 09<br>
<font color='0000ff'>正常チェック</font><br>
==========<br>

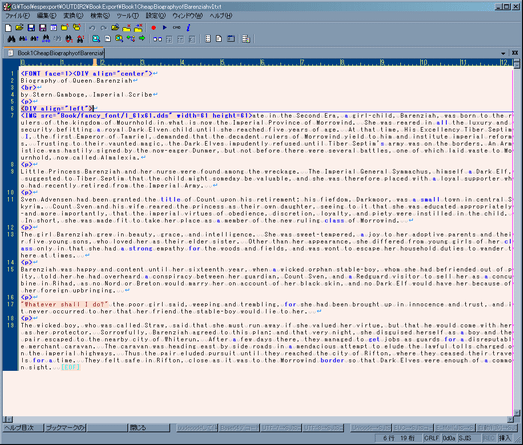
飾り文字 †
書物の段落の頭で用いられている装飾アルファベットは画像で実装されています。
以下はその一覧です。
Book/fancy_font/a_70x61.dds
Book/fancy_font/b_60x61.dds
Book/fancy_font/c_59x61.dds
Book/fancy_font/d_80x61.dds
Book/fancy_font/e_78x61.dds
Book/fancy_font/f_59x61.dds
Book/fancy_font/g_68x61.dds
Book/fancy_font/h_62x62.dds
Book/fancy_font/i_51x61.dds
Book/fancy_font/j_60x61.dds
Book/fancy_font/k_61x61.dds
Book/fancy_font/l_61x61.dds
Book/fancy_font/m_65x62.dds
Book/fancy_font/n_63x62.dds
Book/fancy_font/o_69x62.dds
Book/fancy_font/p_59x62.dds
Book/fancy_font/q_67x62.dds
Book/fancy_font/r_73x62.dds
Book/fancy_font/s_61x62.dds
Book/fancy_font/t_52x61.dds
Book/fancy_font/u_66x62.dds
Book/fancy_font/v_63x62.dds
Book/fancy_font/w_69x62.dds
Book/fancy_font/x_69x62.dds
Book/fancy_font/y_62x62.dds
Book/fancy_font/z_66x62.dds
補足:その他 †
- 日本語化パッチでは半角スペース( )をゲーム内で改行として扱います。ゲーム内で半角スペースを表記したい場合はアンダースコア(_)を使います 現在はこの処理は不要の模様(日本語化パッチの改良により不要となった模様)
- ダブルクォート(")はBooks以外では使用してはいけない禁止文字です。
訳文では使うべきでないでしょう。
どうしても使いたい場合は[QUOTE]という文字列を使えばゲーム内ではクォート文字に置換されて表示されます
- 台詞をキャラによって特徴付けようとしたい場合はCSで該当箇所を当たるのがセオリーです。
exportしたデータだけでは誰の発言か分かりません。
- 翻訳作業はテキストエディタで行う事を推奨しておきます。
可能ならば内部コードがUnicodeな物がベストです。
タブ区切りテキスト文書なのでMS OfficeのExcelやOpenOffice.orgのCalcでも処理できますが、
その場合は文字化けを起こす部分を先ず直しておきましょう。
ExcelやCalcの独自形式を用いれば良いかもしれませんが(未検証)、少なくともタブ区切りテキスト文書のままでは問題が発生すると思われます
(素のテキストなので複数の文字コードの混在が事実上不可能)。
- 日本語化パッチ使用時に全角スペースが文字化ける事があります。発生条件は不明です(OBSE?)。半角スペースを使用した方が良いかもしれません(アンダースコアでも良いが、文字列処理が不便になる)。
- 翻訳が他のModの動作に(一般的な競合のほかにも)影響を及ぼす事が有ります。
良くあるのはNames等の名詞の翻訳です。
例えば、"Steel 〜〜"という武器を預けると強化して"Fine Steel 〜〜"にしてくれる鍛冶屋Modが有ったとしましょう。
この場合、受け取り品が何かをチェックする部分はそのアイテムのFormIDを見ればよいです。
ところが、"Steel 〜"な武器全般である事を一発で知る簡単な方法は有りません。
そこで全てのSteelな武器のIDをScriptに書く必要があります(とてもめんどくさい)。
ところが、OBSEを使うとアイテム名で判別が出来るようになります。
つまり『Steelが名前についている』という条件で判定できるようになりModderにとってはとても楽になります。
さてここまで来てようやく本題です。
この鍛冶屋Modと名詞を完全に日本語化するModを併用した場合の事を考えましょう。
日本語Modでは"はがねのつるぎ"になっていたとします。
さて、鍛冶屋Modにその武器を渡して上手くいくでしょうか。
当然ですね、動作しません。
これはMod間のボタンの掛け違いによるものであり、仕様とされる挙動です。
バグとは言いません。
これを解決するにはどちらかを諦めるか、鍛冶屋Modを日本語Modに対応させるしかありません。
このような事例は多くはないかもしれませんが、翻訳を行う事で他のModの挙動に影響をおぼよす可能性がある事は覚えておいた方がよいでしょう。
[E] importとセーブ †
CSは基本的に日本語表示には対応していません(一部出来る部分も有る)。
これに有志の作のパッチを当てる事で日本語表示を可能にする事が出来ます。
ここで用いている画像の
CSは有志作ではなく自分向けに作成したパッチ
(文字化けの解消と表示サイズを多少弄る程度)を当てています。
手順 †
- 翻訳データをimportしたいesp/esmファイルをOpen
espファイルの場合は"Active File"でopenしないとファイルを編集できないので注意

- 作成した翻訳データをimport
ScriptMessageboxes、Books以外の項目はこれだけでOK
- Booksの翻訳を組み込み
Booksはメニューからimportが可能。
その場合はOblivionディレクトリ中にあるBook Exportディレクトリにimportしたいデータを放り込んで行えばよい。
但しこの場合、書物に対応する物が無いファイルがあった場合はエラーが出る(importファイルは "書物のID.txt"となる)。
またCSの仕様と思われるが、importした書物には冒頭に"<div align='left'><br>"が、行末に<br>が付加される。
HTMLモードを使用したくない場合は邪魔である。
しかも設定等で切る事は出来ない。
これを何とかしたい場合は
『CSから対象の書物を開いて手作業で張っていく』
のがオーソドックスな手法である(面倒だが)。
そして実はもうひとつ解法があり『CSの
実行ファイルへのバイナリ修正』である。これを行うと上記タグ自動追加機能を殺せるようになる。
この方法はOblivionの日本語化パッチ内の添付文書に有るので目を通すと良い

- Named Scriptをセーブ(Compile)
OblivionのScriptにはNamed Script
(CSのメニューから開けるScript Ediorで編集するもの)
と、Result Script(QuestやDialogueに付加されるもの)の二種類がある。
先ずは前者から。
Scriptで押えておくべき共通事項は、
『編集するだけでは変更はゲームに反映されず、セーブ(Compile)しないといけない』
事である。
また、
『必要なデータだけをセーブ(Compile)すべし』
という事も重要である。
これは何故かというと、CS編集時はVanillaなデータもロードされているがそれらを変更しなければ保存時にModには反映されない(これは感覚的に理解出来る筈)。
しかし、Scriptに於いてはセーブ(Compile)を行う事が即ち変更と見做されるのか、Modに保存されてしまうのである。
全くScriptのコードに触れなくても、である。
勿論このModに組み込まれてしまう分は容量の無駄になる訳である。
よって、翻訳データが入っているScriptだけをセーブ(Compile)すべき、という事になる。
さて、以上の事を押えてようやく以下本題に移る。
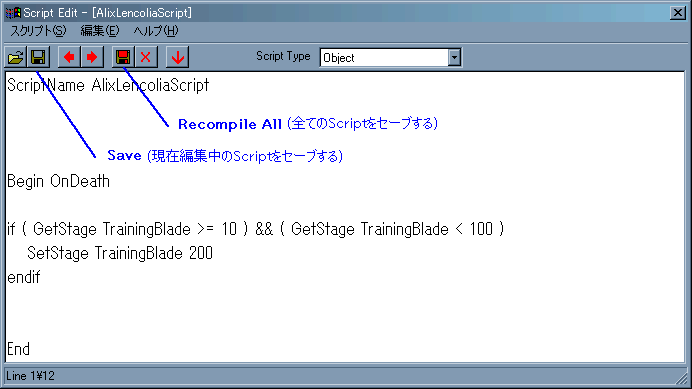
Named ScriptはCSのメニューから開くエディタで編集する。
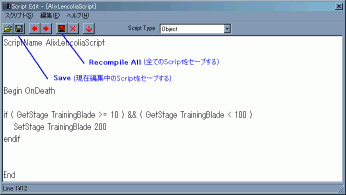
この画像でSaveのボタンを押せばScriptはセーブされる。
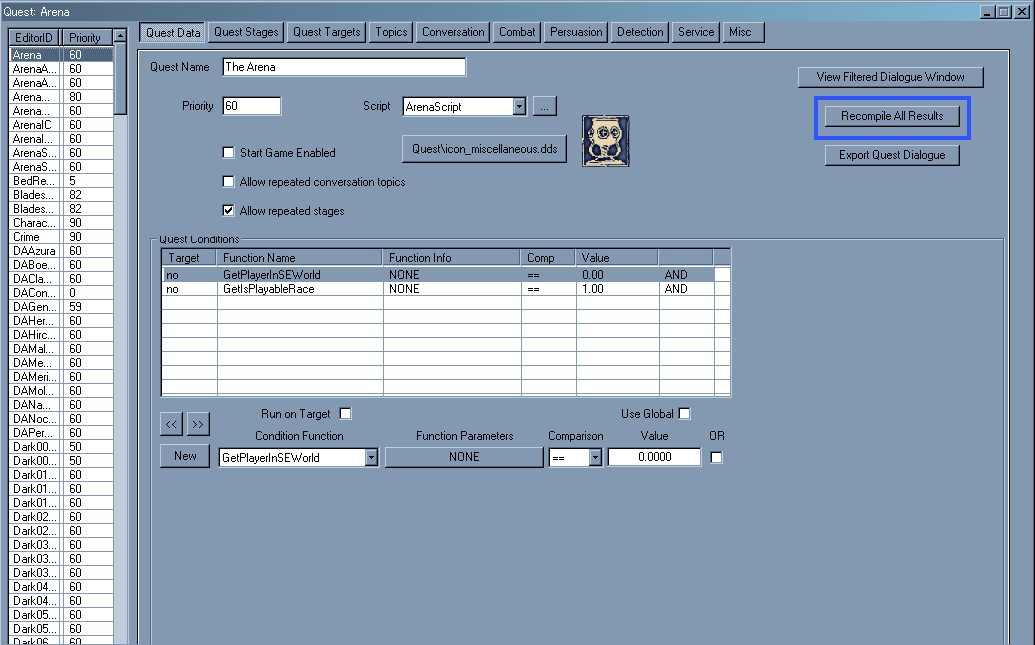
しかし、右のRecompile Allは押してはいけない。
これを押すとVanilla内の翻訳にも関係ないScriptも含めて本当に全てがModにセーブされてしまうのである。
つまりScriptが重複する事になり、無駄にサイズが増大するのである(大体+3MB)。
よって基本は、翻訳データの組み込まれたScriptを特定し、一つ一つセーブ(Compile)するのが普通の解法である。
Scriptの特定は上で述べたScriptMessagesのExportデータのフォーマット解説が参考になるだろう。
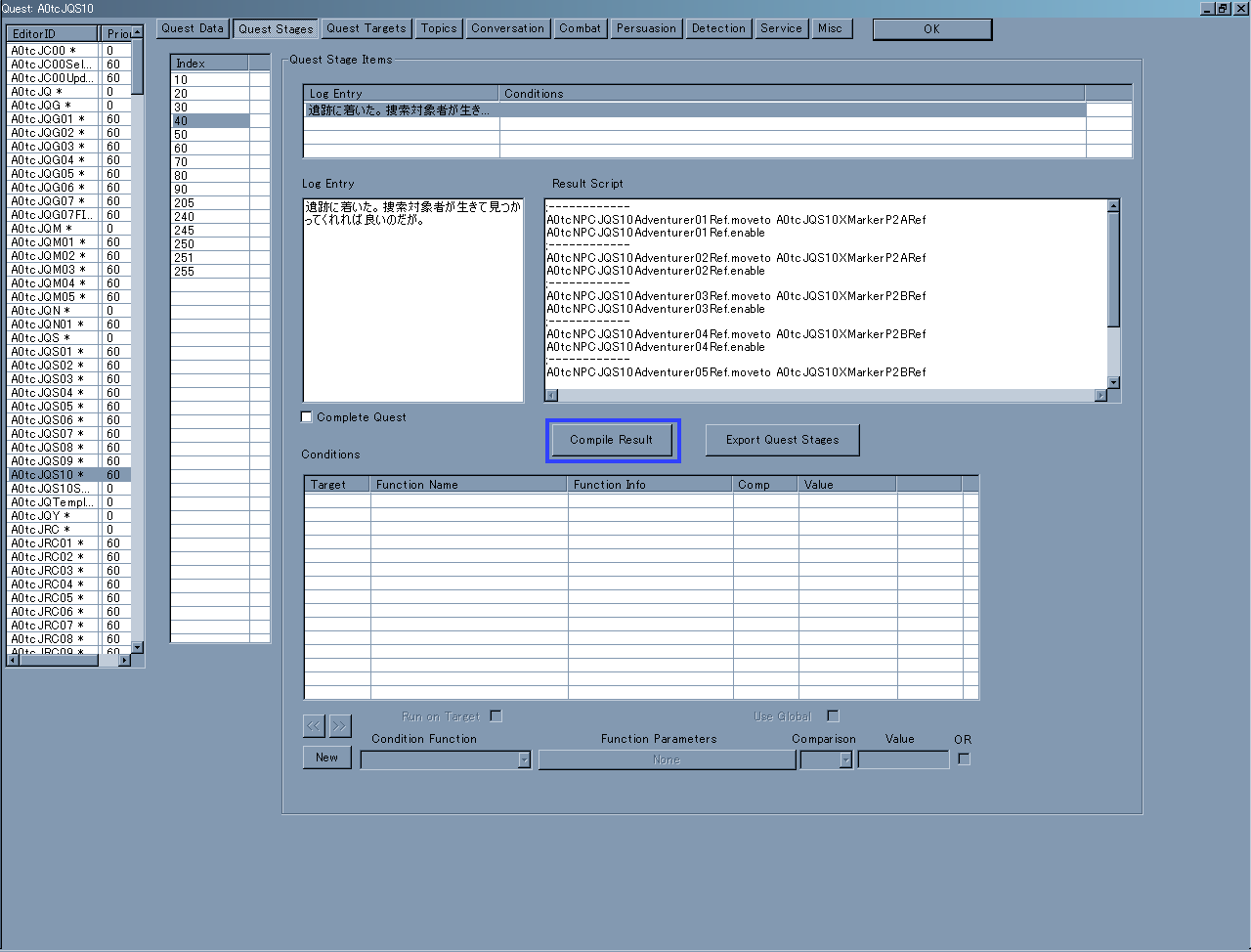
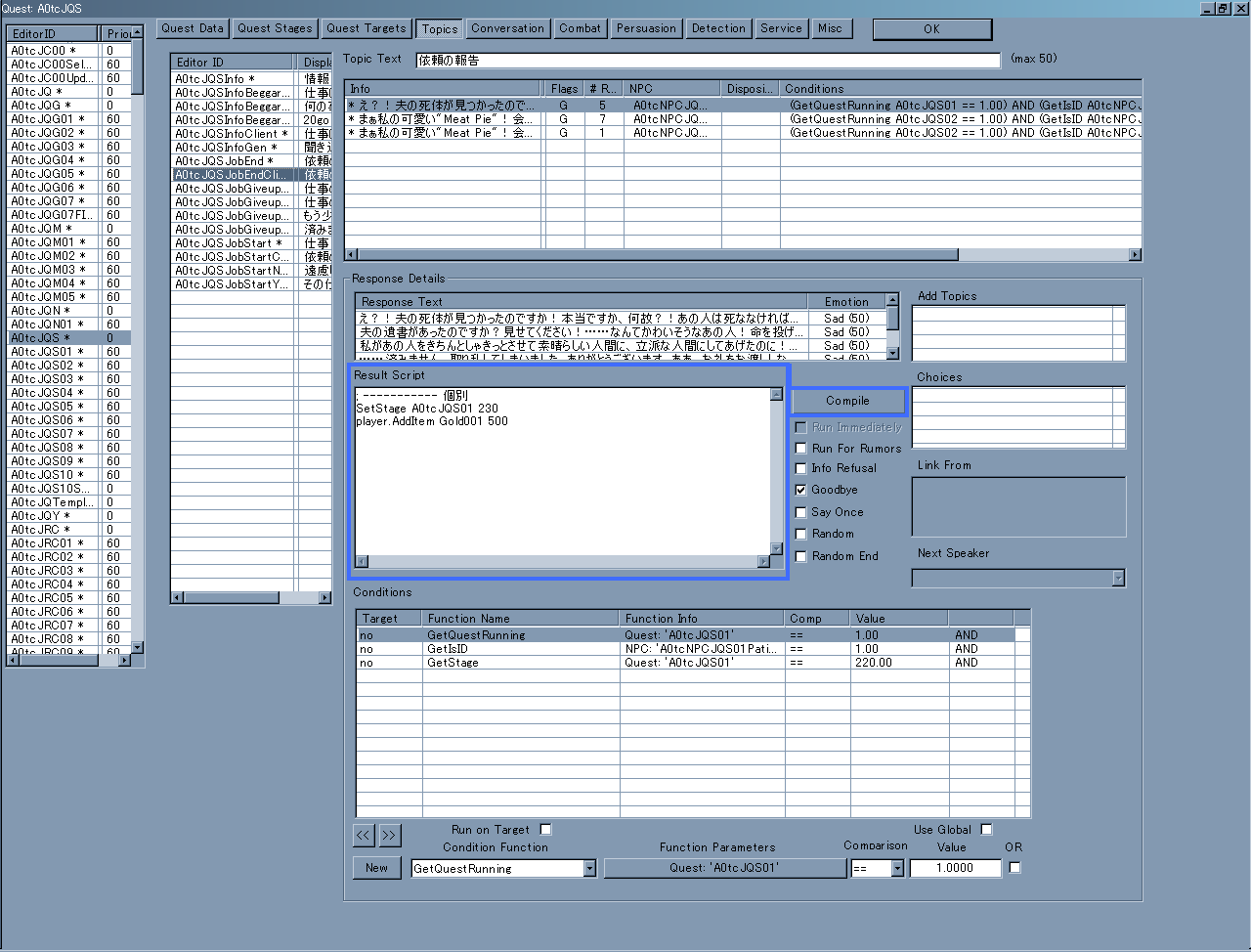
- Result Scriptをセーブ(Compile)
Result ScriptはScript Editorからは編集もセーブも出来ない。
よってNamed Scriptとは別作業となる。
Result Scriptは2箇所に有る。
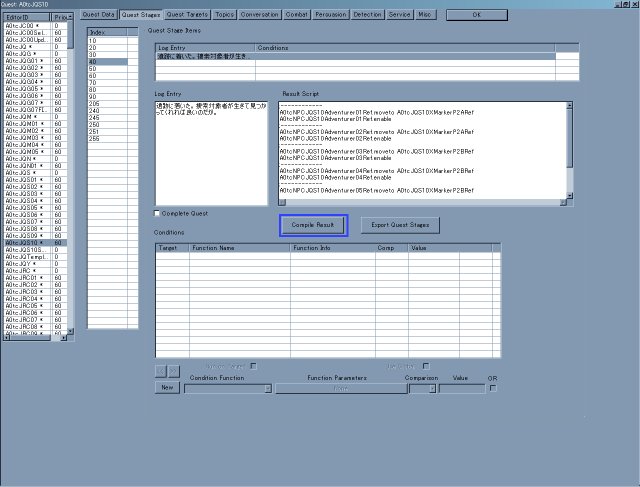
先ずはQuest Stageに付与されているものが一つ
(MenuBar → Character → QuestsのQuest Stagesボタン)。
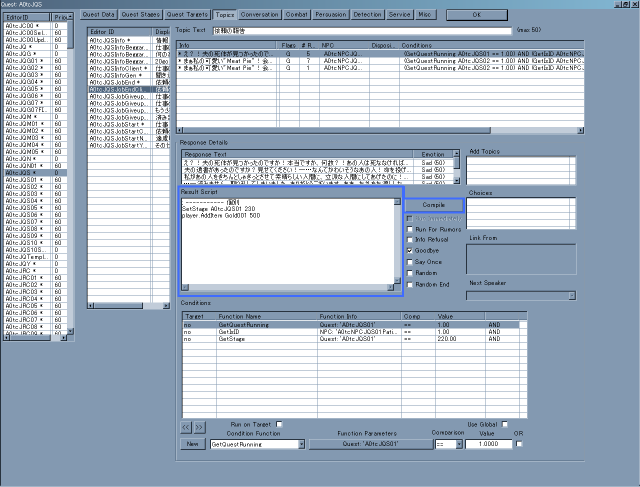
もう一つはDialogue(台詞)に付与されているもの
(MenuBar → Character → QuestsのTopicsやConversation等のボタン、或いはMenuBar → Character → Filtered Dialogue)。
これらも基本はNamed Scriptと同じく翻訳データの組み込まれたものをちまちまとセーブ(Compile)していく事になる。
Result Scriptも『Recompile All』に相当する方法は有る。
以下の画像の『Recompile All Results』がそのボタンである。
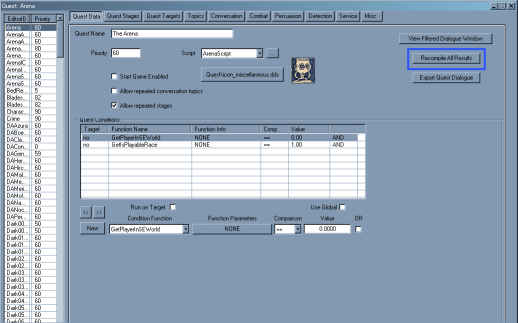
ただ、こちらの場合はModにそれらのResult Scriptが貼り付けられたQuest(やDialogue)が存在しなければModに組み込まれない様なのでNamed Scriptよりは余り気にしなくても良いかもしれない。
また、Named Scriptの『Recompile All』より警告を出すレベルが甘いように思われる。
これらは本格的に使用したことが無いので当方では未検証。
- Modをセーブ
ツールバーのセーブボタンかメニューバー(File → Save)からセーブして完了。
翻訳対象がesmの場合は新規espの保存になる。
翻訳対象がespの場合は上書きで良い。
補足:Scriptの簡単なセーブ方法 †
さて実際に上の作業をして『どのScriptに翻訳データが入り込んでるのか分かるかっ!』と絶望する方。
Yes yes yes!! 多分みんなそう思っています。
確かにExportしたデータ記載のFormIDやEditorIDを辿ればどのScriptに組み込まれる翻訳文かは当たりを付ける事が出来ます。
しかし、それは極めて面倒でもあります。
そこで、発想の転換、『全部セーブしてVanillaと重複するのだけ削除』しちゃえばいい。
『全部セーブ』は上の『Recompile All』と『Recompile All Results』で出来ます。
では『Vanillaと重複するデータ』の削除はどうすれば良いのでしょう?
方法は3つあります。
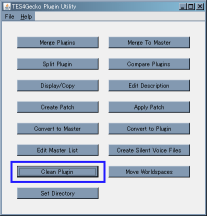
『TES4GeckoでClean Plugin』『Wrye BashでDecompile All』『TES4Editで手動で削除』です。
- TES4GeckoでClean Plugin
操作は簡単。次の画像で強調されているボタンを押して処理したいファイルを選んで実行するだけ。
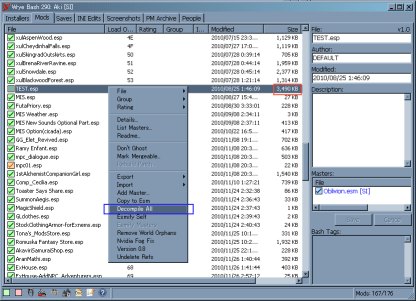
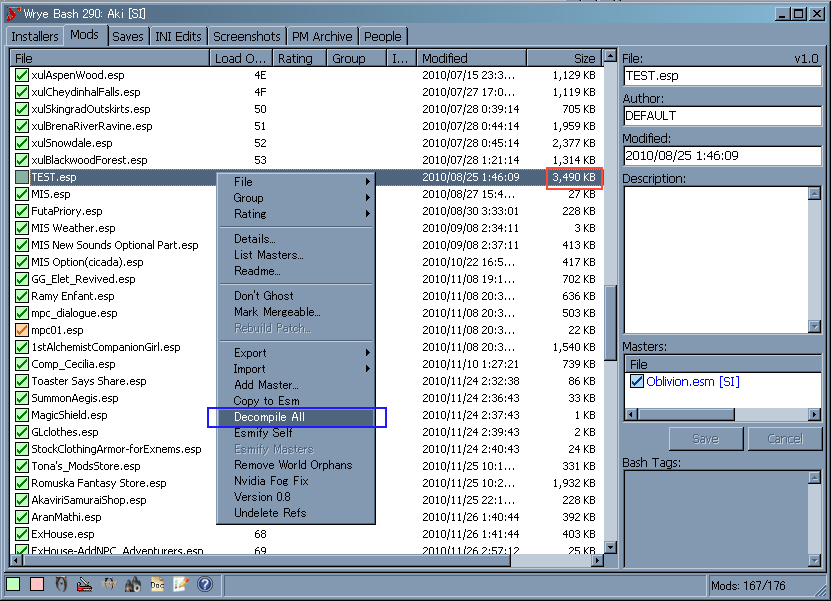
- Wrye BashでDecompile All
操作はこれも簡単。次の画像で強調されている項目を選んで実行するだけ。
この画像では TEST.espのサイズにも注意して下さい。
これはOblivion.esmをOpenし、何も変更を加えないで『Recompile All』だけを行って保存したファイルです。
何も考えないで行うとそれだけ無駄なサイズが増加するという事がお判り頂けるかと思います。
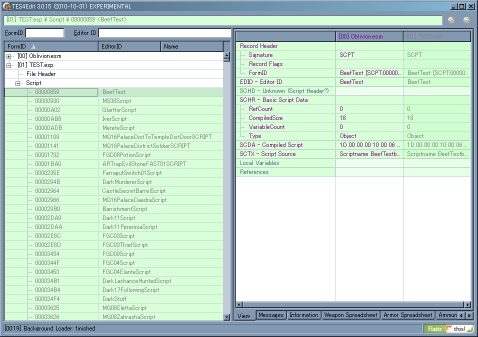
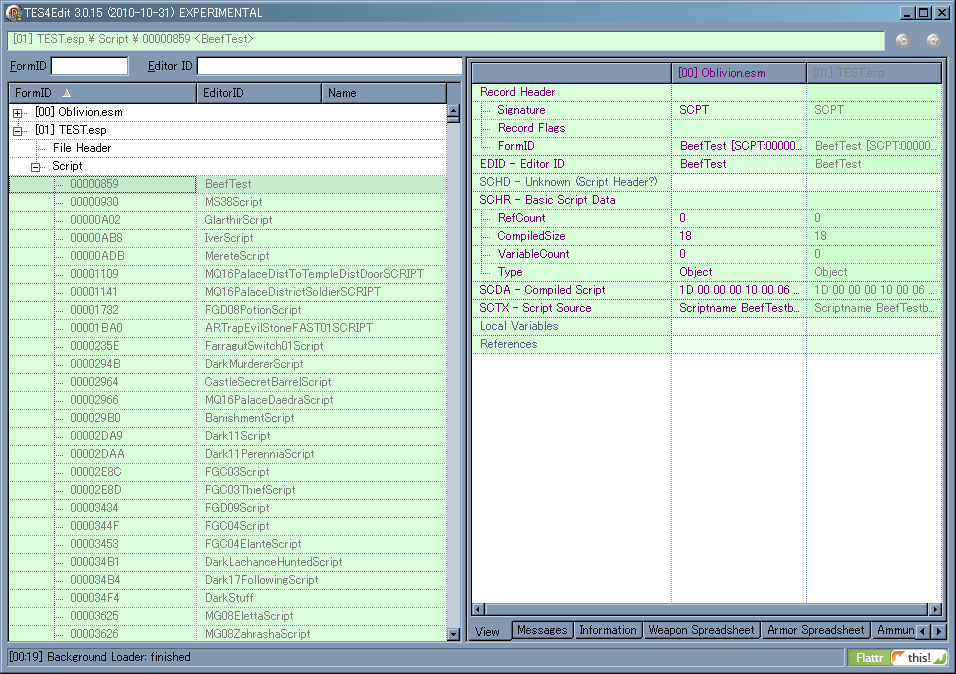
- TES4Editで手動で削除
これは重要度を自分で判定できる熟練者向き。
TES4Editを使えばどのデータが何で上書き等されているか分かります。
例の画像では全て緑になっていますが、黄色や赤になる事も有ります。
緑は同一内容のデータであるという意味です。
よって大抵は削除して良いです(黄色は別の値で上書きされている事、
赤は上書きされた上にまた別の値で上書きされている事を示す)。
ただしTES4EditのScriptカテゴリはNamed Script(CSのScript Editorから触れるもの)のみを含みます。
Result Script(Quest等に付加されている物)はそこではなくDialogue TopicやQuestのカテゴリをチェックしなくてはなりません。
Result Scriptは上の説明で書いたとおりあまり気にする必要はないようですが。
- 注意
TES4GeckoやWrye Bashで掃除したあとTES4Editで見るとまだ緑なデータが残っている事が何度かありました。
気になる人はTES4Editでの最終チェックを行っておくと良いかもしれません。
また、VanillaなScriptの一部はCompileが通らないものがありますがModの翻訳を行う際は気にする必要はありません
(理由:Scriptコンパイル後にそのScriptの扱うObjectのEditorIDを変更したりすると発生する現象。
コンパイル済みScriptはEditorIDではなく恐らくFormIDでObjectを特定しているのでそれでも問題が無いという訳である)。
補足:Shivering Islesの有無とScript †
- Shivering Isles(SI)導入環境が要求されるScript(Mod)をSIなし環境でセーブ(Compile)するとSI環境ではまともに動かないScript(Mod)になる可能性があります。
これはv1.2系のOblivion向けのModをv1.1系のCSで編集した場合も発生すると思います
(v1.2系から追加の関数がある為)。
特にこちらはScriptのみならずCondition判定でも使用されるので危険性は高いはずです。
これらの問題は完全に解明されている訳ではありません
(SIは本体にマージされる形なのでその様な事例は検証が困難)。
SI非導入環境で翻訳に興味が有る方はこの点に十分気をつけなくてはいけないでしょう。
補足:OBSE拡張使用のScriptのセーブ †
- OBSE
を使用したScriptの場合は
OBSE
から
CS
を起動しなくてはセーブ(Compile)が出来ません。
これは結構重要です。
- Scriptのセーブを行った
OBSE
のバージョンがプレイヤーにも要求されるようになる事があります。
例えばオリジナルが
OBSE
0016で開発された物だったにも拘らず翻訳Mod作成者の環境が
OBSE
0019だった場合、Mod利用者にとって不必要な更新を要求する事になり、余り望ましい事ではありません。
ましてやベータ版
OBSE
を使用したなんて場合は面倒の元になりかねません。
利用者側でScriptをCompileし直して貰えばとりあえず解決はしますが。
確かに翻訳程度でそこまで気にする必要は無いかもしれませんが、ちょっとの努力で回避できる事であれば配布側でやっておく価値は十分にあると思います。
OBSE
の古いバージョンは
OBSE
開発サイトでもDL出来るようになっています。
尚、
OBSE
の拡張関数を使用しないScriptはこの問題は発生しないように思われます
(VanillaなScriptを
OBSE
を通してCompileし、TES4Editで比較という形で検証)。
また、このバージョン間問題はOBSE 0018から0019の移行時によく見られます。
検証していませんが0019以降はコンパイル済みデータに互換性がなくなっているのかもしれません。
- OBSE
から
CS
を起動した場合、Scriptの文法チェックはノーマルよりも厳しくなります。
Vanillaに存在するScriptのセーブ(Compile)でもほぼ確実にWarningの嵐になります。
気になるかもしれませんがVanillaなScriptはとりあえず動いているので
Modの翻訳程度で手を出す必要は無いと思います。
- Wrye Bashを用いると色々なデータをExportできますが、Scriptも選択できます。
これはScriptを書くModderには極めて有用(CSはScript自体のexportが不可能。
よって、esm/esp内のScriptを参照したい場合に極めて不便。検索もしにくいし)なのですが翻訳で使用する事も出来ます。
ExportしたScriptは同じくWrye BashでImport出来るのでScriptを見つつ翻訳を行いたい場合にはかなり有用なのです。
或いは、CSでExportできないOBSE関数を使用したScriptの翻訳をする場合にも有用でしょう。
ただ、OBSE関数Exportはespexportで可能なので敢えて面倒なこちらの手法を使う必要性は高くありませんが。
どちらかというとScript系Modderにとって有用な知識かもしれません。
尚、ImportしたScriptはセーブ(コンパイル)作業が必要です。
補足:Scriptそのほか †
- 翻訳には余り関係無いですが、CS上でのScript編集可能サイズには上限があります。
Named Scriptはコメントも含め36kB付近で、
Result Scriptはコメントも含め1kB付近のようです。
元からサイズが大きいScriptを翻訳するような時には気にしないといけないでしょう
- Scriptのセーブ(Compile)は現在もCS上でしか行えません。
TES4Edit等でも不可能です。
これは他のカテゴリとの大きな違いなので注意が必要です。
- Scriptのimportは関数部分の一致はチェックして無いらしいです。
例で説明しましょう。
MessageBox "TITLE (%g, %g)", Var01, Var02, "BUTTON A", "BUTTON B", "BUTTON C"
というコードが有る場合は普通
FormID: 01234567 HogeScript MessageBox 10 0 TITLE (%g, %g)
FormID: 01234567 HogeScript MessageBox 10 1 BUTTON A
FormID: 01234567 HogeScript MessageBox 10 2 BUTTON B
FormID: 01234567 HogeScript MessageBox 10 3 BUTTON C
という風にexportされます。
これを翻訳する場は
FormID: 01234567 HogeScript MessageBox 10 0 タイトル (%g, %g)
FormID: 01234567 HogeScript MessageBox 10 1 ボタン A
FormID: 01234567 HogeScript MessageBox 10 2 ボタン B
FormID: 01234567 HogeScript MessageBox 10 3 ボタン C
となります。しかし、「importは関数部分の一致はチェックして無い」ので例えば
FormID: 01234567 HogeScript MessageBoxTekitou 10 0 タイトル (%g, %g)
FormID: 01234567 HogeScript MessageBoxTekitou 10 1 ボタン A
FormID: 01234567 HogeScript MessageBoxTekitou 10 2 ボタン B
FormID: 01234567 HogeScript MessageBoxTekitou 10 3 ボタン C
でも問題なくimportが出来るようです。
これはOBSE追加関数等を処理する場合に使用されていました。
しかし、今ではespexportのOBSE追加関数への対応が十分である上に、
Wrye BashによるScriptのexport/import機能も有るのでこのような小技を使う事は無いと思います。
補足:ConstructionSetあれこれ †
翻訳に関わりそうな色々
- ConstructionSet.ini
- 自動バックアップ
- 設定:File → preferences → Misc → Auto Save every [*] minutes.
- バックアップ場所(自動的には作られない):Oblivion\Data\backup
- その他
補足:その他 †
- esmファイルに対して日本語を行った場合、新たにespファイルが作成されます
- espファイルに対して日本語化を行った場合、直にそのespファイルが編集されます
- espファイルに対する日本語化を別のespファイルで行なう事は(トリッキーな方法を行なわない限り)出来ません。これは基本的にはespファイルから別espファイルを参照できない為です
- espファイルに対する日本語化を別espファイルで行なうにはWryeBashを使い、オリジナルespをMasterに追加する事で可能となります
(CSではespファイルをMasterファイルに出来ない為、WryeBashを使用する)。
但し、これは公式Toolでは提供されて無い手法なので予期せぬ不具合が発生する可能性が有ります
- import後に余計なゴミを入れていないかTES4Editで調べておく事をお勧めしておきます。
CSにはデータのimportを行うと弄ってない部分まで変更が加わったようになってしまうという
不具合が時々報告されるからです。
[F] 公開 †
手順 †
- 配布するファイルを作成
補足:日本語化のデータの配布方法としてまとめたので参考の事。
- ドキュメントを作成
翻訳作業者のメモやサポート情報・利用規定・クレジット・オリジナルに関する事の情報等は書くべき。
オリジナルへのリスペクトを忘れずに
- 配布アーカイブを作成
アーカイブ形式(圧縮形式)は作成者の好みで良いが、
圧縮率を考慮しつつ一般的なアーカイバでも対応している形式を選択するのが好ましいだろう
(例えばACE形式とか普通に解凍出来る人は多くない)。
OblivionのMod界隈ではRARや7-ZIPが良く見られる。
7-ZIPは無料で利用できる上に圧縮率も高いので良く使われるのだが
『7-ZIP形式の知名度が比較的高くない』
『圧縮メソッドによっては解凍時にメモリを多量に消費する(PPMdの最高圧縮設定が特にヤバイ)ので解凍環境を選ぶ事がある』
(7-ZIPの公式Toolで圧縮すればメモリ消費量を案内してくれるので要チェック)、
『開発途上の形式なので7-ZIP対応と謳っているアーカイバでも解凍できない事がある』
(特に統合アーカイバプロジェクトDLLを使用せず独自実装をしている物に多い)
という点に注意する必要は有る。
RARはリカバリレコードが使えるので破損に強いが有料ソフト(rar形式だけの為に4,000円弱を高いと見るかどうか)なので元々所持していた場合等以外はお勧めしにくい(展開はフリーソフトでも可能)。
- 公開
お好きな場所に。
問題回避の為に或る程度コントロールできるようにしておく事が望ましい
(自分のサイトに置くとか、アップローダでもきちんと削除キーを設定しておくとか)。
ObMMでウィザード形式にする場合はOblivion Mod ManagerのScriptも参考になるかもしれません
補足:日本語化のデータの配布方法 †
方法は幾つか有ります。当方が考えるメリットデメリットを書いておきますので参考にしてください。
尚、基本的にオリジナルModの製作者の意思を尊重するという行動方針で考察を行っています。
作者の意思を考慮しないのであればこの考察は参考にならないと思います。
世間には色々な人が居ます。
『二次配布?改変?いくらでも勝手にやってくれ!あ、良い改善案有ったら教えてね』
『作った物に責任を持ちたいから配布は全部自分でコントロールしたい…』
『これは俺様のだ。文句は言わせぬ。改変なぞ許さぬ。パクり禁止!パクっただろって?知らんがな』
『俺の大作が狙われている。天災な俺の素晴らしい芸術を奪おうとするヤツが居る。対抗する為に協力してくれないか。夜に教会の裏に来てくれ』
とか。一般論では語りにくいものです。
しかし、創造への敬意を示し彼の意思を尊重する事は、たとえそれがその時点では
面倒に感じたとしても、結果的に関わる全ての人を(色々な意味で)幸せに出来る良い
選択であると信じています。
一般的な注意事項 †
日本語化する事でエンバグしてしまった場合、オリジナル作者に苦情、若しくは
悪意が向かう可能性が有る事に注意しなくてはならないでしょう。
日本語化が原因だと気付きづらい不具合も発生する事はありえます(VanillaではNamesのRACEカテゴリの件)。
利用者側での原因の切り分けは恐らく期待すべきではありません。
また、エンバグではなく利用者のミス(例えばバージョンが違うModに適用した、等)であったとしても
その様な危険性は有り得ます。
加えて、利用者は案外添付文書を読んでくれないものです。
しかし、だからといってドキュメントを書かない事の理由にはなりません。
最低限の情報は記述しておくべきです。
尚、二次配布や改変が作者により禁じられているModもあります。
その場合は個人で楽しむ場合を除き、配布を遠慮した方が無難と思われます(「こっそり」等であっても)。
また、二次配布や改変に制限が加えられているにもかかわらず『日本語化ファイルは二次配布とか自由です』という風にしてしまう事も宜しい事ではないと思います。
配布方法:『日本語化したデータをオリジナル作者に提供』 †
作者側でリリース状況を完全にコントロールできるのはメリット。
利用者側でも(恐らく)日本語版を作者側から入手できるので楽。
唯一のデメリットはオリジナル作者への連絡。
多分、面倒だって思う人は多いはず。
配布方法:『esm/espファイルだけ日本語化したものに差し替えて全ファイルを配布』 †
利用者にとってはAll in Oneなので利用しやすい。
しかし、オリジナルMod製作者の同意を得られるかは微妙な所。
また例えば二次配布されているものにバグが有った場合、オリジナル作者側の行動が多少煩雑になります。
そして、大抵のModは結構サイズが大きいものです。
配布方法:『オリジナルのesm/espを日本語化し、それだけ配布』 †
日本語化手法としては
基本的方法02と
イレギュラーな方法01がこれに該当します。
利用者にとってはちょっと不便。
とはいえ、オリジナルを入れて上書きすれば良いだけなのでそんなに悪くも無いでしょう。
しかし、オリジナル作者側の印象的には微妙なところかもしれません。
最大のデメリットは利用者がバージョンが異なるオリジナルModに
日本語化したファイルを上書きしてしまう可能性がある事です。
バージョンが近ければ大抵は問題は無いでしょうが、
データファイルのディレクトリ構造を一新したりしていた場合は結構大変な目にあうだろう事は想像出来ます。
また、ドキュメントを読まないタイプの人がesp/esmだけ導入して
『まともに動かない』と誤解したりする可能性も有ります。
配布方法:『日本語化したespファイルだけ配布』 †
日本語化手法としては
基本的方法01'と
イレギュラーな方法02がこれに該当します。
何が上と違うのかと言うと、
『Modオリジナルなesm/espは弄らずにそれらを参照するespファイルの形で提供する』
事です。
利用者にとってはちょっと不便。
対象がesmファイルの場合はそう難しくありませんが(JPWikiMod.espが良い例)、
espファイルのModに対しては幾らか困難になります。
それは
CSではespファイルをマスターとしたespファイルを作成できないからです
(つまり、確実性を保障されている方法ではない)。
Wrye Bash等を用いればespに対するespファイルの作成は出来ます。
しかし、そのようなespファイルを
CSで編集するとマスター情報が抜け落ちてしまうので
再度設定する必要が出てきます。
この手法のデメリットは、利用者がespファイル単体で事足りると誤解する可能性があること、
espファイルへの日本語化espファイルはイレギュラーな方法である事に加え利用者にロードオーダーに対する注意を要求する事
(Masterにしたespより日本語化espファイルは後にすべき)が挙げられます(omodのScriptを使えば提供側でロードオーダーを指定する事は可能。使用者側ではWrye Bashが使える)。
また、重度のMod中毒User(多分褒め言葉)は導入済みesp/esmファイルがかなり多い事が予想され、
仕様上限の255個に近くなっている可能性があります。
そのような場合はこの手法は余り好まれないでしょう。
配布方法:『esp/esmファイルへの差分パッチ形式』 †
日本語化手法としては
基本的方法02と
イレギュラーな方法01がこれに該当しますがそれ以外の手法でも使用は可能です。
利用者にとっては幾らか不便。
特にバージョンが異なると利用できなくなるという部分が嫌われます。
一番のメリットは日本語化espファイルの配布という形式で発生するデメリットの殆どを回避できる事です。
また、『必ずオリジナルのModを作者の公開場所からDLしてくる必要がある』状況にする事で
利用者と作者の接触の機会を設けるという効果も有ります
(esm/esp単体のModの場合はこうしないと実現できない)。
付随効果として、ファイルサイズも節約できるので公開側にも優しいです。
デメリットは複数のesm/espを含むModやウィザードが親切で様々な導入形態を
許しているものの場合、パッチ作成労力が増大する事です
(例えば5つのespで構成されている場合、5つのパッチが必要になる。
更に『どれか一つ』では無く『要る物だけ入れる』という形で、
ウィザードが親切でマージ化されたespも提供されていたら更に泥沼。
組み合わせの数は 2^5 = 32。流石にこれはオリジナル作者側も厄介だから
無いとは思うが)。
配布方法:『import用テキストでの配布』 †
利用者にとっては不便。
利用にはある程度の知識が要求されるのも問題です。
ですが、訓練されたベトコン…じゃなくてOblivionプレイヤーならそれを元にバージョン違いのModにも適用させる事が出来たりするので通には喜ばれる形態
補足:差分ファイル作成アプリ †
差分ファイル(パッチファイル)として公開する場合、以下の
必要/便利なソフトで紹介するアプリを使う事になると思います。
ここではその2つのアプリを使用する際の押えておいた方が良い知識に触れます。
WDiff †
WDiffは古くから存在する差分ファイル作成アプリです。
この差分ファイルのアイコンを目にした方も多いのではないでしょうか。
現行版は1998年に作成されたWindows95用の物です。
古い上に現行Windows向けに作成されているものではないとはいえ、そのような不安要因を全く感じさせません。
このアプリのメリットは、差分ファイル作成やその適用が容易である点です。
差分ファイル作成は最初は迷うかもしれませんが、理解してしまえばほぼワンパターン化できます。
差分適用も差分ファイルを対象のファイルがある場所に放り込んでダブルクリックで完了する明快なものです。
但しメリットばかりではありません。
差分を当てるファイルが大きい場合、『メモリが不足している』というエラーが出てパッチを当てられなくなる事例が報告されています。
これは各個のPC環境に大きく依存するもののようなので根本的な解決は不能と思われます。WDiffは全てをメモリ上で処理するらしいです。
よって旧ファイルと新ファイルのサイズを足した分以上の空きメモリが最低でも必要になるのが理由のようです。
メモリ開放系のアプリで対処してダメなら物理メモリを増やすかしかない気がします。
udm差分ファイル作成ツール †
udm差分ファイル作成ツールは比較的新しい差分ファイル作成アプリです。
これはシェアウエアですが、個人的且つ非営利な利用であれば自由に使えます。
このアプリのメリットはプロファイルを作れる事があげられます。
日本語化パッチは何度も作り直す事が多いものです。
その作業毎にファイルを指定して、設定して…という手間をするのは非常に面倒くさいです。
ところがこのアプリでは差分を作る設定をプロファイルとして保存できる為、そのような作業が極めて容易になります。
また、複数ファイルへのパッチ作成も可能など機能は極めて豊富です。
添付文書に目を通して検討する必要は十分にあります。
デメリットはWDiffの様な操作性(対象ファイルがあるディレクトリに差分ファイルを置いてダブルクリックで完了)は実現できない事です。
基本的にはパッチを使用する人が対象ファイルのあるディレクトリを指定してあげる必要があります。
これはユーザにとってのデメリットになりますが差分を当てる時だけにしか要求されないのでそう忌避するほどの物でも無い気がします。
WDiffで発生するメモリ問題もこちらに起こるかは未検証です(少なくとも発生するという報告を見た事は無い)。
尚、このアプリには差分データを圧縮する機能がありますが、それを行わずに配布アーカイブの方で圧縮した方が最終的なサイズが小さくなる事例が多いです(差分ファイル内の圧縮はzlibを使用しているらしいが、7-zip等と比べると劣る面が多い)。
オリジナル作者への連絡のススメ †
可能な限りした方が良いでしょう。
ドキュメントに『許可は要らないよ』と有っても
『ヘイ、ユーのワンダホーなModをじゃぱにーずに翻訳してるぜ、喜んでくれ!せんきゅー!』
位は知らせてもばちは当たらないと思います。
『りありぃ?せんきゅー!実は私、18のメリケンのハイスクールガールなんだけど貴殿にふぉーりんらぶ!でござる!ハラキリ、ゴクモン、カリフォルニアロールさいこー!』
と翻訳から始まる故意…じゃなくて恋が産まれるかもしれません(効果は人によって異なる事を当社はお知らせいたします)。
冗談さておき。
大抵の方は翻訳を喜んでくれます。
場合によっては便宜を図ってくれます。
オリジナルの配布所で宣伝してくれる事もあります。
確かに面倒です。
でも日本語字幕を再度英訳して出来をチェックして駄目出しをした
某映画監督みたいな
事を要求するModderは居ないと思うので怖がらなくても良いです。
多分居ないと思う。居ないんじゃないかな。まちょっとは覚悟しておけ。
作者への敬意という意味で連絡を取る方が望ましいのは確かでしょう。
ただ、それ以上に同じ趣味を持つ人との交流とそれによって得られる物は
お互いの貴重な財産になるのではないかと私は思います。
Readmeのススメ †
『〜が分からないんだけど?…え?添付文書読め?めんどくさい…』
『添付文書?Mod作るのに集中したいからめどいです』
いや分かります、その気持ちは。
私だって基本ものぐさですから。
しかし、例えそうであっても最低限の添付文書は書くべきかと思います。
ライセンスがどうだとかうざったいとか、許可を得ないでやったものだから
こっそりしたいとかいう主張も有るでしょう。
でもそれ以後に誰かがその産物を利用したいと考えた場合にその様な言及が無い場合は
(普通に判断する場合は)躊躇せざるを得ません。
世の中にはいろんな人が居ます。
意思は言葉にしないと表現できないのです。
そして現実に書かなかったことで起こるツマラナイごたごたが如何に多かった事か。
当事者達が問題にしていないのに外野がもめる事程無駄な事はありません。
それをあなたが故意に起こしたいと思っているのなら別ですが、そうではないでしょう?
ちょっとした作業で未来のごたごたの芽を刈り取る事が出来るならめっけものじゃないですか?
え?
それでもめんどくさい?
宜しい、では次に例を挙げましょう。この程度でも多分十分ですよ
(行ごとにPOPUPで説明でます)。
■ つくったひと:Adoring Fan
■ ばーじょん :v0.01
■ リリース :2011-01-01
■ らいせんす :作者に断ってないので二次配布とか無しね。shyから流れたらおしまいで
■ れんらくさき:スレで声掛けたら召喚されるかも?
■ びこう :作者から許可貰ってないの。誰かかわりに交渉してくれたら嬉しいな
■ くれじっと :****(〜さん作)、****(〜さん作)、ありがとー
自信の有る出来で無いとか事情が有って、とかで再利用とかして欲しくなければ
その旨を正直に書いて良いと思います。
口うるさい外野も多いでしょうが、それが不当な理由で無ければ大体の方は
分かってくれます。
また、文書を書く際は重要な部分に関しては出来るだけ平易な文章にすべきです。
仮に海外の方が利用する可能性が出てきた場合、砕けすぎた日本語では
機械翻訳が効かず、意味が通じなくなってしまいます
(例えば『れあdめ』は日本人はすぐわかるでしょうが、海外の人には理解しがたいでしょう)。
伝わらなきゃ意味なんて無いに等しいのです。
全く別の観点ですが、添付文書を書いているとそれがフィードバックを起こして本来の
生成物に良い影響を与える事もあります
(仕様を頭の中から文書という形に変換する過程で仕様の粗が見えてきて
生成物の改善に繋がるというのは良く有る事)。
世の中にはReadme作成支援ソフトなるものも有るみたいです。
探してみると良いかもしれません(当方は使ってないので詳しい事は不明)。
さあ、皆さんも添付文書道を極めてみませんか?!
Oblivion Mod 翻訳所というサイトがあります。
これは当方が管理しているWikiなのですが、コンセプトは『くらえ!じんかいせんじゅつ!!』です。
最近のModderはかなり精力的な方が多く、翻訳側としてもその膨大なテキスト量を喜びつつも絶望する事があります。
その様な場合、一人でやるよりも皆でやってしまえば良いのです!
勿論集団作業である関係上或る程度のルールはあります。
しかし、それは翻訳自体を制限するものではなく、集団作業を円滑にするだけの為に存在するものばかりです。
翻訳の隅々にまで自分の意思を統一させたいというような凝り性の方には向いていないかもしれません。
しかし、自分では紡ぎ出せなかったすばらしい言の葉に見える事が出来るかもしれません。
Oblivion Mod 翻訳所では有志の参加をお待ちしております。








{kind=link}